数据导入工具
一个项目可能拥有大量的历史数据需要接入。当需要导入GB级甚至TB级的数据时,采用本地导入方式显然会比网关导入更加明智。我们的提供的数据导入工具,就是这样的一个可视化解决方案。
新建导入任务
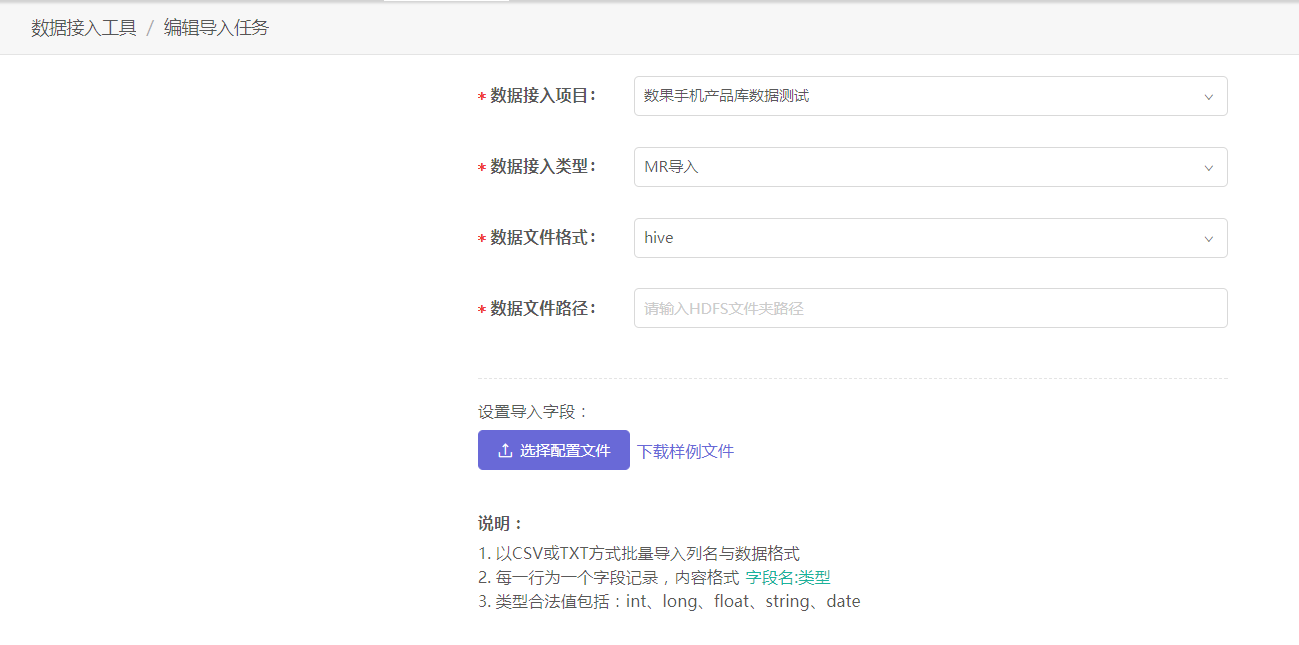
当我们需要为指定项目导入本地数据时,可新建一个导入任务,并进行下列设置:
- 数据接入项目:选择需要被导入数据的项目;
- 数据接入类型:目前支持的类型为“MR导入”,即hadoop的map reduce方式,用于接入HDFS文件;
- 数据文件格式:支持hive格式或csv格式;
- 数据文件路径:设置数据文件的路径。若设置为文件夹路径则会尝试导入文件夹下的所有文件。
- 设置导入字段:通过上传CSV格式的配置文件,来设置需要导入的字段列名及其数据格式。具体文件格式可下载样例文件进行参考。
当正确上传配置文件后,页面会发生变化,展示出配置文件的内容及更多的设置选项:
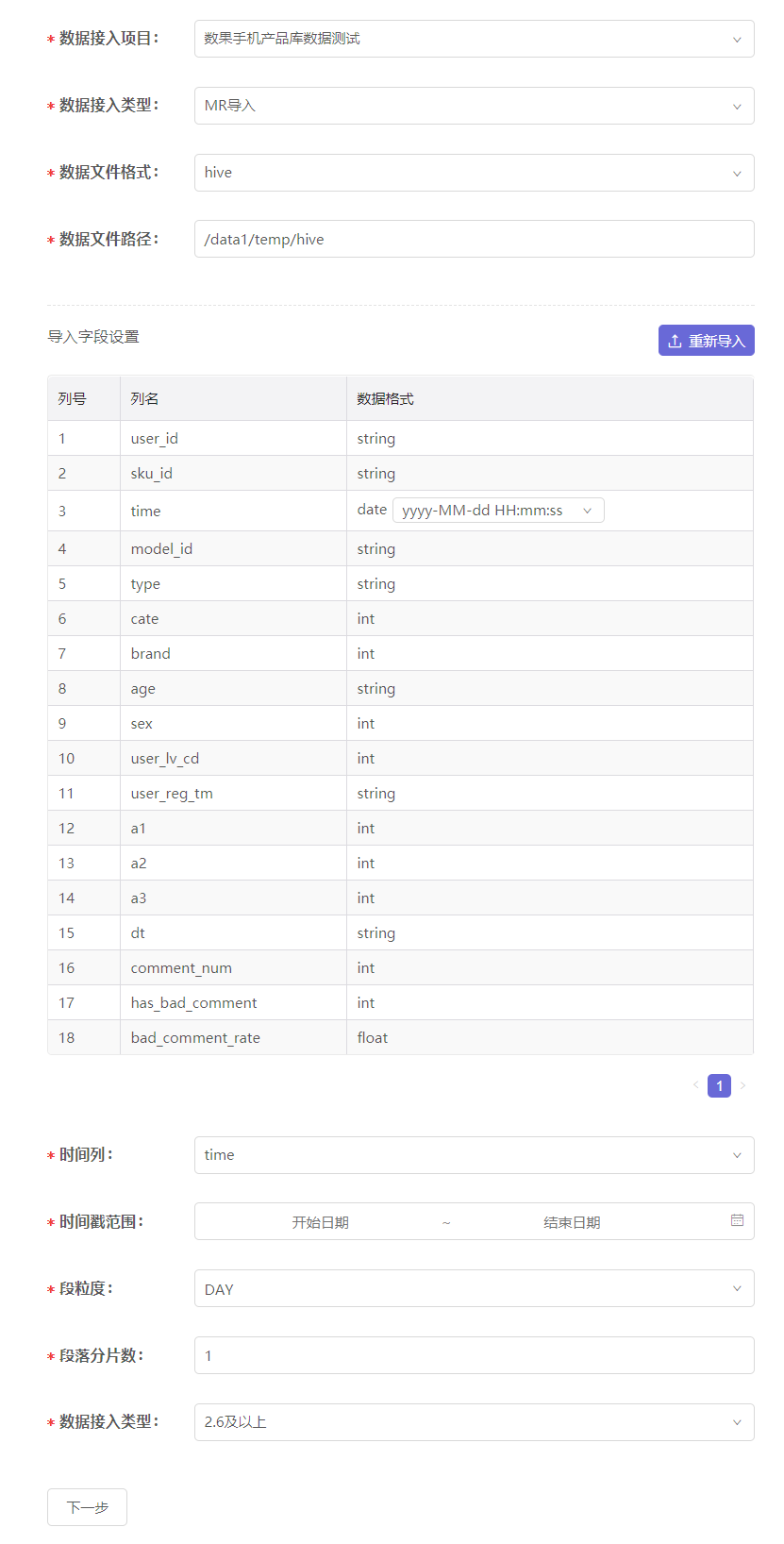
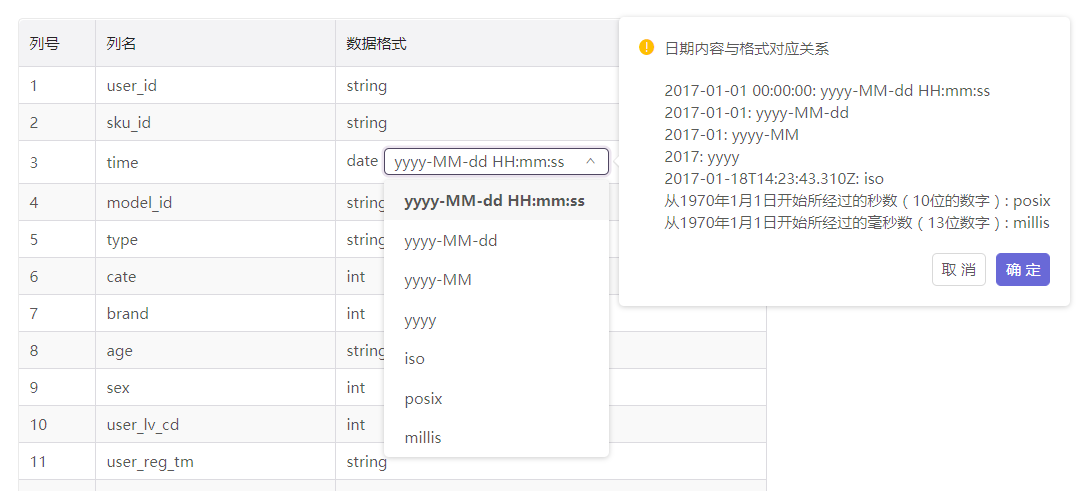
我们需要根据实际数据的情况,对数据格式为date的导入字段进行时间格式的设置:
时间戳设置:我们需要为此份数据指定时间戳列,即将时间列的数据作为项目的时间轴看待。同时,要对时间戳列进行一些设置:

- 时间戳列:从导入字段中指定某一列作为时间戳列,只能指定数据格式为date的列;
- 时间格式:自动与所选的时间戳列保持一致;
- 时区:时间戳列数据的来源时区,默认为中国的东八区(UTC+08:00);
- 时间戳范围:设置时间戳列数据的覆盖范围,超出范围的数据将会被抛弃。请设置与实际所需数据相符的时间戳范围。
粒度设置:设置数据的分段粒度,合理的分段有助于最优化导入速度和实际使用性能。建议最终设置的每段数据在500MB左右。

- 数据段粒度:默认是DAY,即按照每天1段对时间戳范围进行数据分段。例如,时间戳范围是2017-07-01至2017-07-31,数据段粒度为DAY,则会将数据分为31段。除了DAY之外,我们还提供了SECOND(1秒)至YEAR(1年)的不同粒度选项。
段落分片数:当经过上面设置后,每段数据依然无法落在500MB左右时,可以通过段落分片数进一步分段。例如,将数据段粒度设置为DAY时,每段数据在1GB左右,那么可以将分片数设置为2,最终每段数据即为500MB左右。
段落分片数的默认值为1,即不影响分段数量和大小。
Hadoop版本:选择正确的版本有助于任务更好的运行。
以上设置完毕之后,点击下一步即可生成脚本代码:
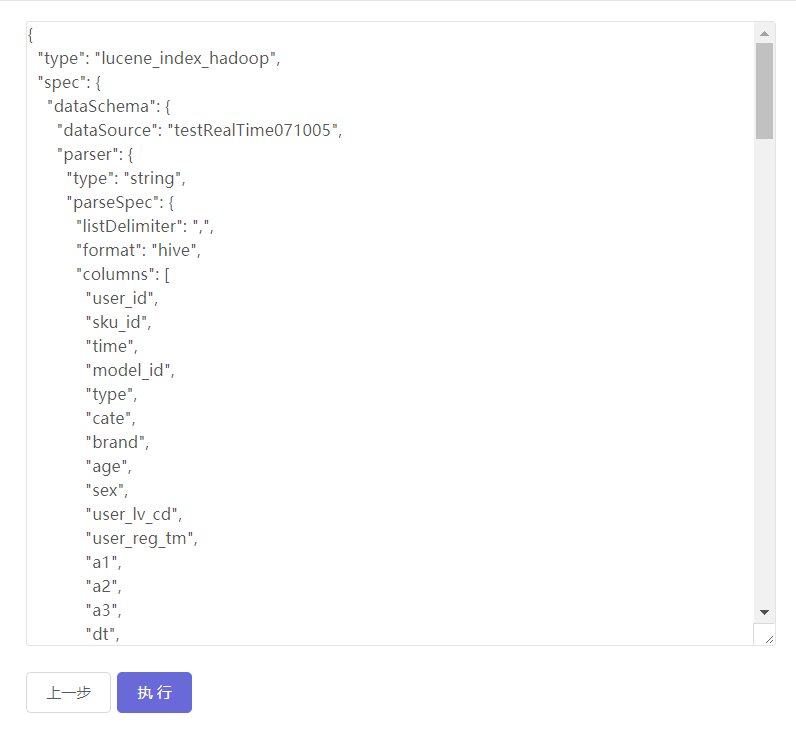
代码可以进行编辑,编辑框的内容即为最终的执行内容。点击执行按钮,数据导入任务即会启动。
数据导入任务列表
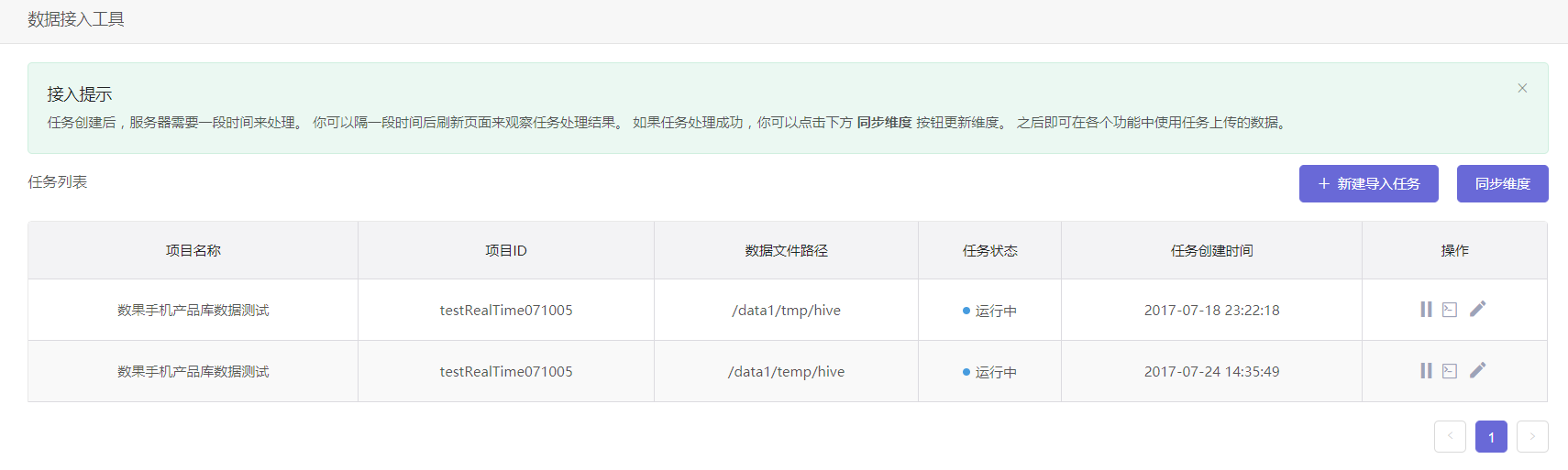
现在让我们回到数据导入工具首页的列表,我们创建的每个导入任务都会陈列在这里。 在任务列表中,我们可以查看导入任务状态,停止任务,修改任务配置,以及重启任务:
- 任务状态: 排队中,同时能够运行的任务数量达到上限时,新的任务默认为排队中状态; 运行中,任务创建并执行后,处于运行中状态,需要根据数据量的大小,花费不同的时间完成导入; 已完成,成功执行完毕的任务; 失败,人工停止或任务失败,停止的任务可以修改配置,可以被重启。
- 停止任务:任务执行过程中允许停止任务,中途停止任务并不会导入任何数据;
- 修改任务配置:已停止的任务可以修改配置;
- 重启任务:已停止和已完成的任务可以再次执行任务,已完成的任务重启将会覆盖此任务之前导入的数据。
特别提醒
数据导入工具导入数据后,需要进行同步纬度的操作,才能在多维分析功能中使用。导入任务成功完成后,请点击任务列表处或维度管理处的同步纬度按钮进行同步。