kafka接入
概要
- 本流程主要演示把
kafka上的url数据导入到Druid。url数据样式:dt=1500714597057&index=163&str=9wevoy(dt的类型为date,格式为millis)前提:
- 部署好druid平台环境
- kafka集群已经部署好,数据已经正常写入特定的topic
- druid集群服务所在网络与kafka集群所在网络是相通的
第一步:编辑json文件
从 kafka 加载数据到 druid 平台,需要通过发送一个 http post 请求到 druid 接入接口。
该 post 请求中包含 json 格式的请求数据信息。为了方便修改,建议先编辑一个 json 文件。
第二步:建立Supervisor
使用 curl 命令发送 post 请求。假设 json 文件名为 wiki.json,curl 命令如下:
curl -X POST -H 'Content-Type: application/json' -d @/tmp/json/wiki.json http://overlord_ip:8090/druid/indexer/v1/supervisor
/tmp/json/wiki.json: 详见
wiki.json
overlord_ip: druid的overlord节点ip地址,如果有多个overlord,必须指定leader的ip.
也可以通过网页来操作:
- 登录 overlord_ip:8090/supervisor.html
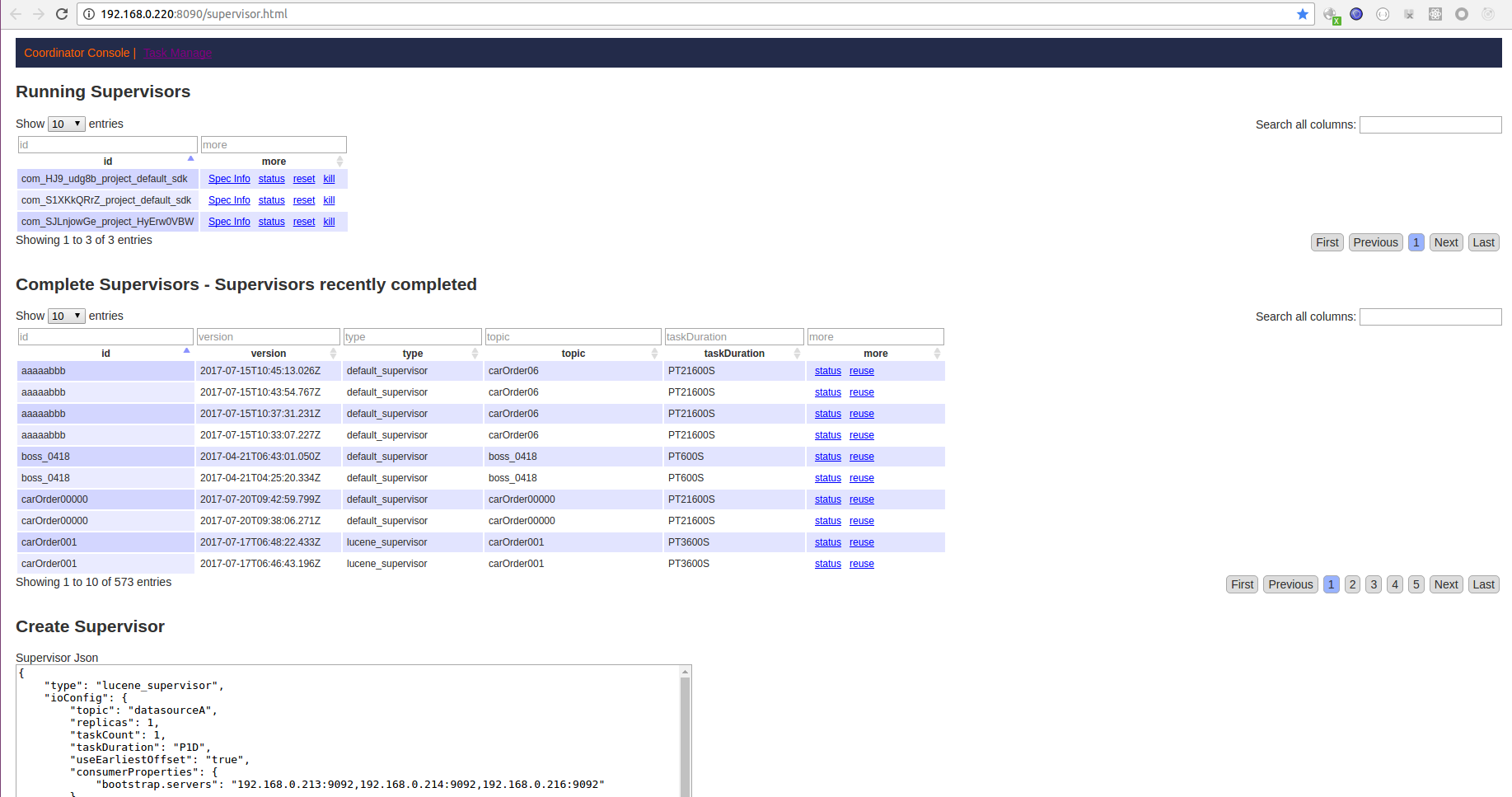
- 删除页面上原来文本框里的内容,将
wiki.json的内容复制,粘贴到文本框中,点击下面的Create Supervisor,即可创建Supervisor。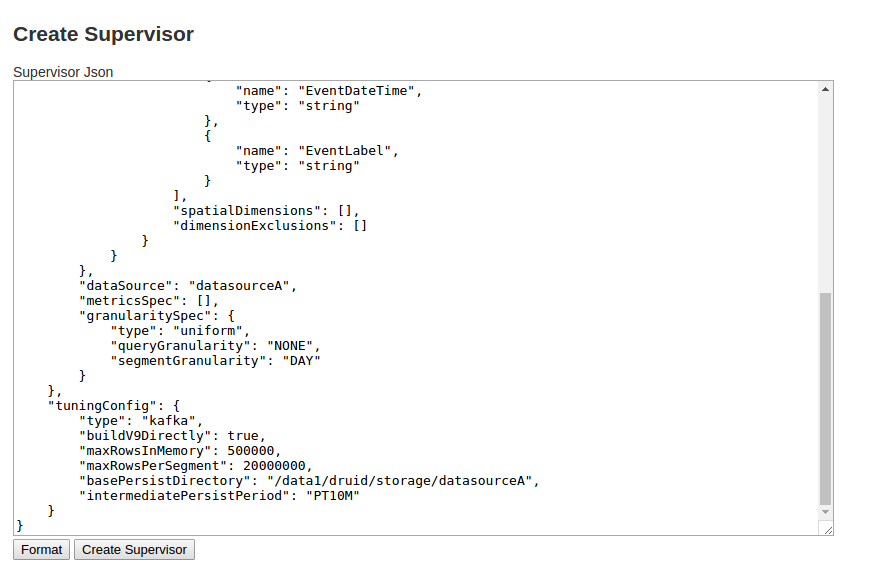
第三步:查看Task执行情况
- 查看日志
访问:
http://{OverlordIP}:8090/console.html,点击Task的日志,查看Task的执行情况OverlordIP: druid的overlord节点ip地址,如果有多个overlord,必须指定leader的ip.

查看执行结果
使用
sugo-plyql查询Task的执行结果,具体的命令格式为:./plyql -h {OverlordIP} -q 'select count(*) from {datasource}'OverlordIP: druid的overlord节点ip地址
datasource:json配置文件中定义的datasource名称如果查询的结果是"No Such Datasorce",则说明数据接入没有成功。
如果数据接入成功,那么查询到的结果如下:
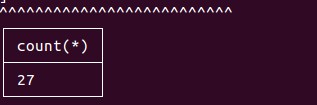
该数字为数据条数。关于
sugo-plyql的安装和使用,详见 sugo-plyql 使用文档
wiki.json文件内容:
{
"type": "lucene_supervisor",
"dataSchema": {
"dataSource": "wiki",
"parser": {
"type": "string",
"parseSpec": {
"format": "url",
"timestampSpec": {
"column": "dt",
"format": "millis"
},
"dimensionsSpec": {
"dimensions": [
{
"name": "index",
"type": "int"
},
{
"name": "str",
"type": "string"
}
]
}
}
},
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "YEAR"
}
},
"tuningConfig": {
"type": "kafka",
"maxRowsInMemory": 500000,
"maxRowsPerSegment": 20000000
},
"ioConfig": {
"topic": "wiki",
"consumerProperties": {
"bootstrap.servers": "192.168.0.220:9092,192.168.0.221:9092,192.168.0.222:9092"
},
"taskCount": 1,
"replicas": 1,
"taskDuration": "PT3600S",
"useEarliestOffset": "true"
}
}
type:从kafka加载数据到druid时固定配置为lucene_supervisordataSchema.dataSource数据源的名称,类似关系数据库中的表名dataSchema.parser.type固定stringdataSchema.parser.parseSpec.formatkafka中单条数据的格式,比如url/json/csv/tsv/hive。url:数据类似url参数串,如:name=jack&age=21&score=78.5&the_date= 1489131528601dataSchema.parser.parseSpec.timestampSpec:时间戳列以及时间的格式dataSchema.parser.parseSpec.timestampSpec.format时间格式类型:推荐millisyy-MM-dd HH:mm:ss: 自定义的时间格式auto: 自动识别时间,支持iso和millis格式iso:iso标准时间格式,如”2016-08-03T12:53:51.999Z”posix:从1970年1月1日开始所经过的秒数,10位的数字millis:从1970年1月1日开始所经过的毫秒数,13位数字dataSchema.parser.parseSpec.dimensionsSpec.dimensions:维度定义列表,每个维度的格式为:{“name”: “age”, “type”:”string”}。Type支持的类型:string、int、float、long、datejson:json格式数据- 数据格式:
{"name":"jack","age": 21,"score": 78.5,"the_date": 1489131528601}
- 数据格式:
csv:csv格式数据dataSchema.parser.parseSpec.listDelimiter:分隔符dataSchema.parser.parseSpec.columns:维度列表,格式:["name","age","score"]
hive:hive数据文件dataSchema.parser.parseSpec.timestampSpecdataSchema.parser.parseSpec.dimensionsSpecdataSchema.parser.parseSpec.separator:维度分隔符dataSchema.parser.parseSpec.columns:维度列表
dataSchema.granularitySpec.type:默认使用uniformdataSchema.granularitySpec.segmentGranularity:段粒度,根据每天的数据量进行设置。 小数据量建议DAY,大数据量(每天百亿)可以选择HOUR。可选项:SECOND、MINUTE、FIVE_MINUTE、TEN_MINUTE、FIFTEEN_MINUTE、HOUR、SIX_HOUR、DAY、MONTH、YEAR。tuningConfig.type:设置为kafkaioConfig.topic:kafka中的topic名ioConfig.consumerProperties:kafka消费端接口的配置,比如kafka的服务器配置taskCount:启动的任务进程数replicas:任务的副本数taskDuration:任务持续时间,超过指定时间后,任务会停止接收数据,等数据持久化之后会创建新的任务进程。可设置的格式:一分钟:PT60S, 十分钟:PT10M, 一天:P1DuseEarliestOffset:从kafka的最早的offset开始消费