项目管理
项目是基础数据的容器,我们提供了多种方式将数据接入项目。同时,所有分析功能都是基于项目进行的。
创建项目
1.点击新建项目,进入新建项目页面。

2.填写项目名称后,即可点击下一步,开始数据接入工作。
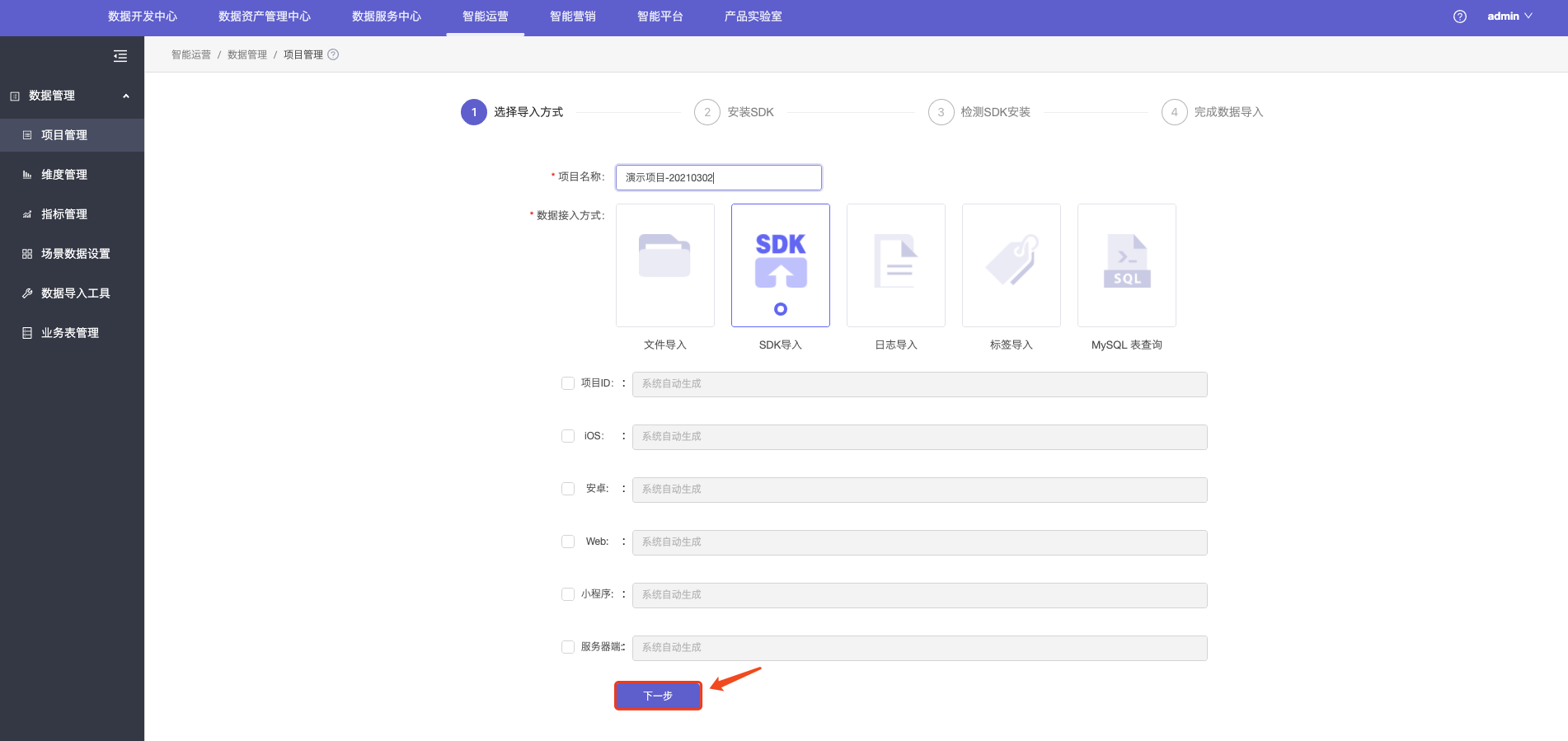
数据接入
目前提供了五种数据接入方式:
- SDK接入:主要针对可视化全埋点数据的接入;
- 文件导入:主要针对小规模数据的导入;
- 日志导入:主要针对服务器日志的采集或历史日志数据的导入;
- 标签导入:标签导入;
- MySQL 表查询:MySQL 表查询;
此外,我们还提供了数据导入工具,便于进行大规模的数据导入。
SDK接入
1.SDK接入管理界面中,您可以看到针对Android、iOS、Web、小程序、服务器端、五种平台的接入管理。点击对应平台的接入说明按钮(此处以Android为例),右侧面板会出现接入说明,请按照文档集成。
可以参见Android 开发者文档与IOS 开发者文档。
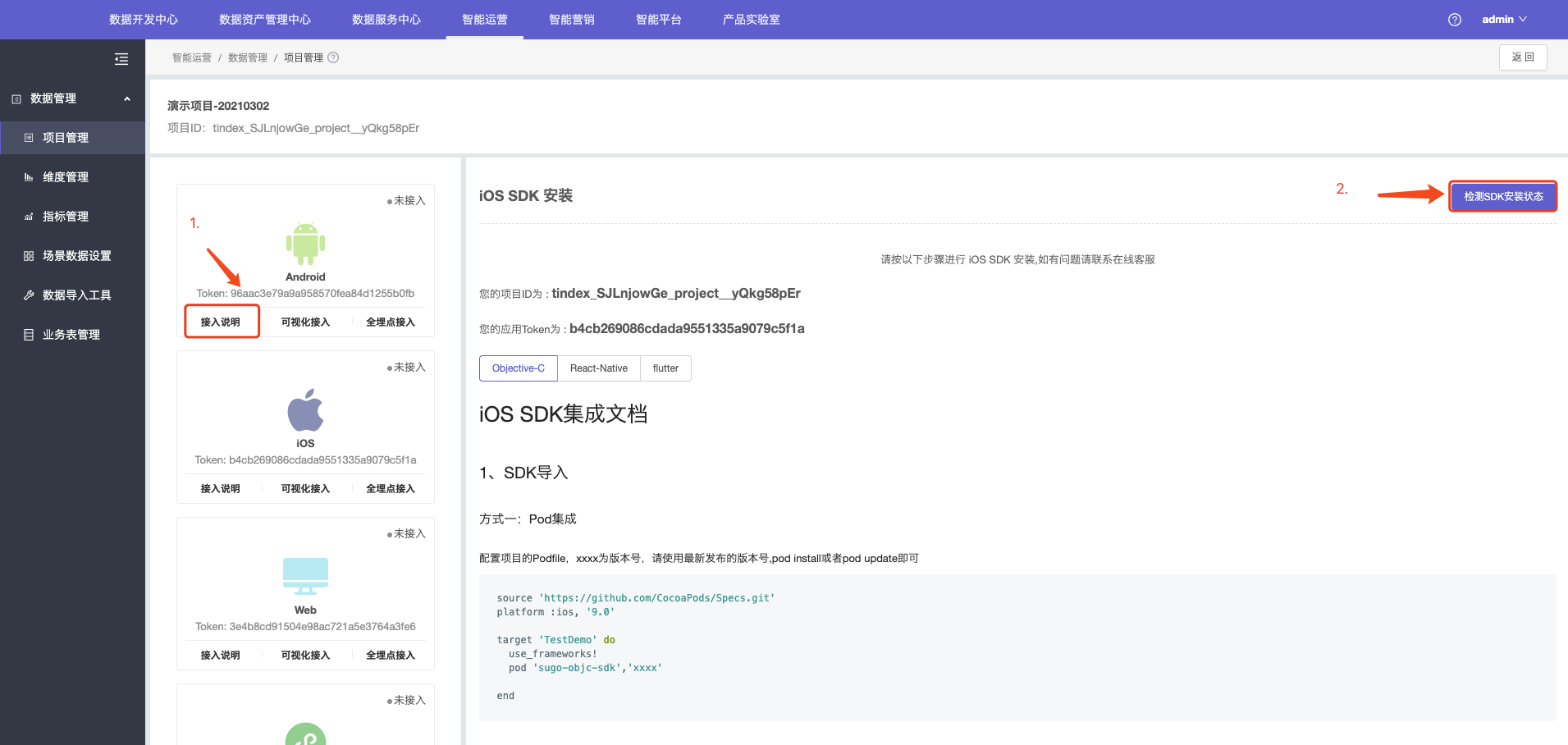
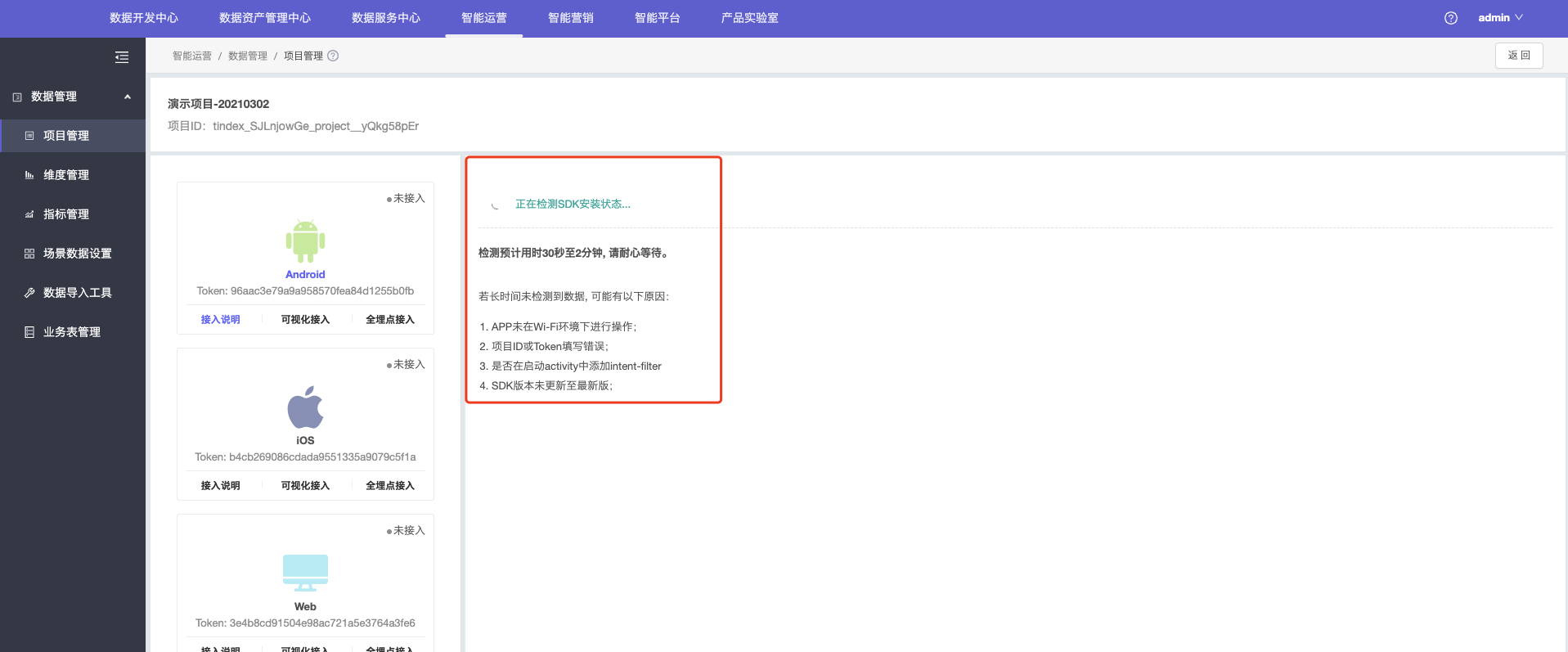
2.当SDK集成完成后,集成此SDK的APP联网重新启动,即可点击“检测SDK安装状态”按钮,SDK检测可能需要30秒至2分钟不等,若检测失败,可按照页面提示进行排查。
APP可视化全埋点
1.点击可视化维护按钮,右侧切换到维护面板
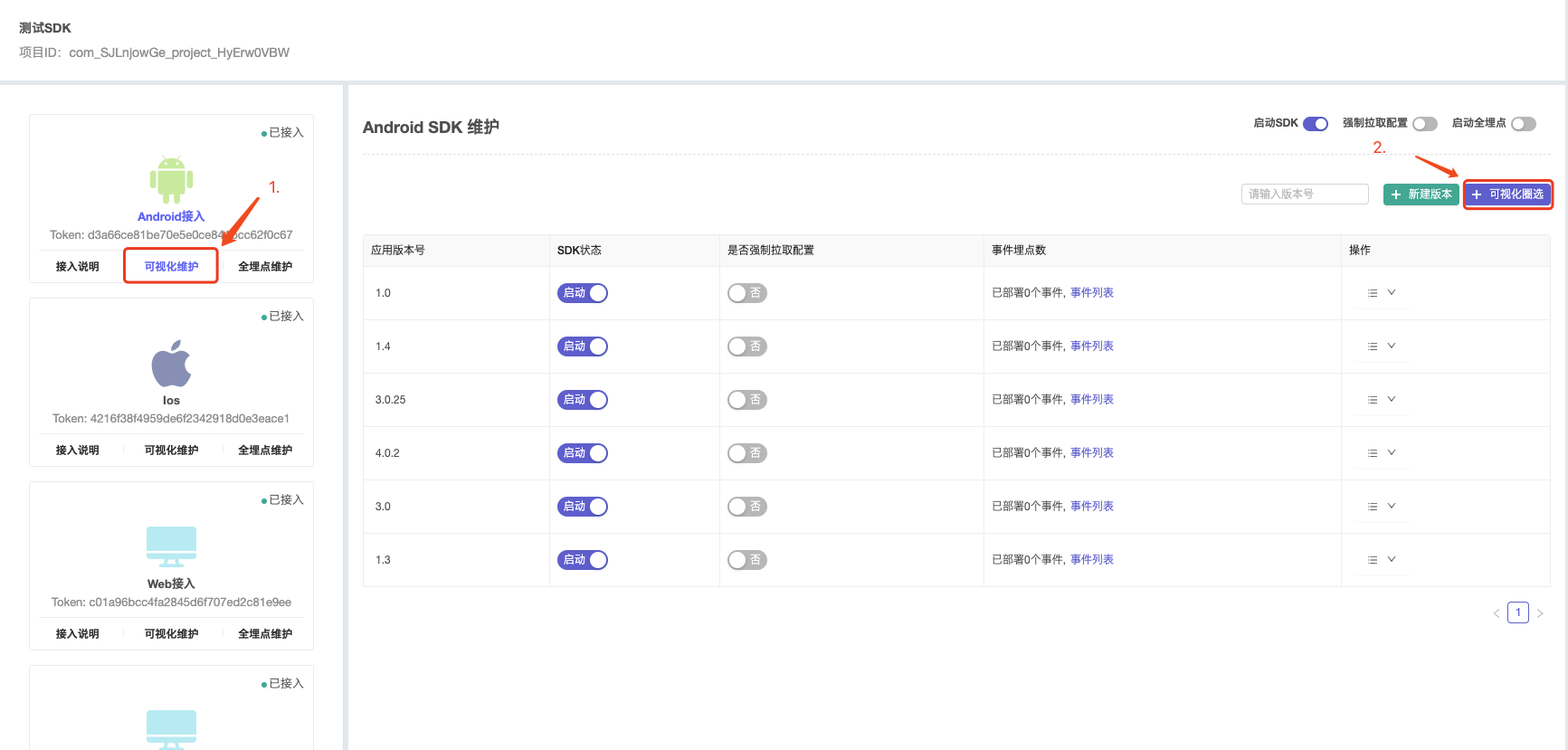
2.右侧面板,点击可视化圈选,用手机扫描二维码之后,打开页面,并按页面提示启动APP。
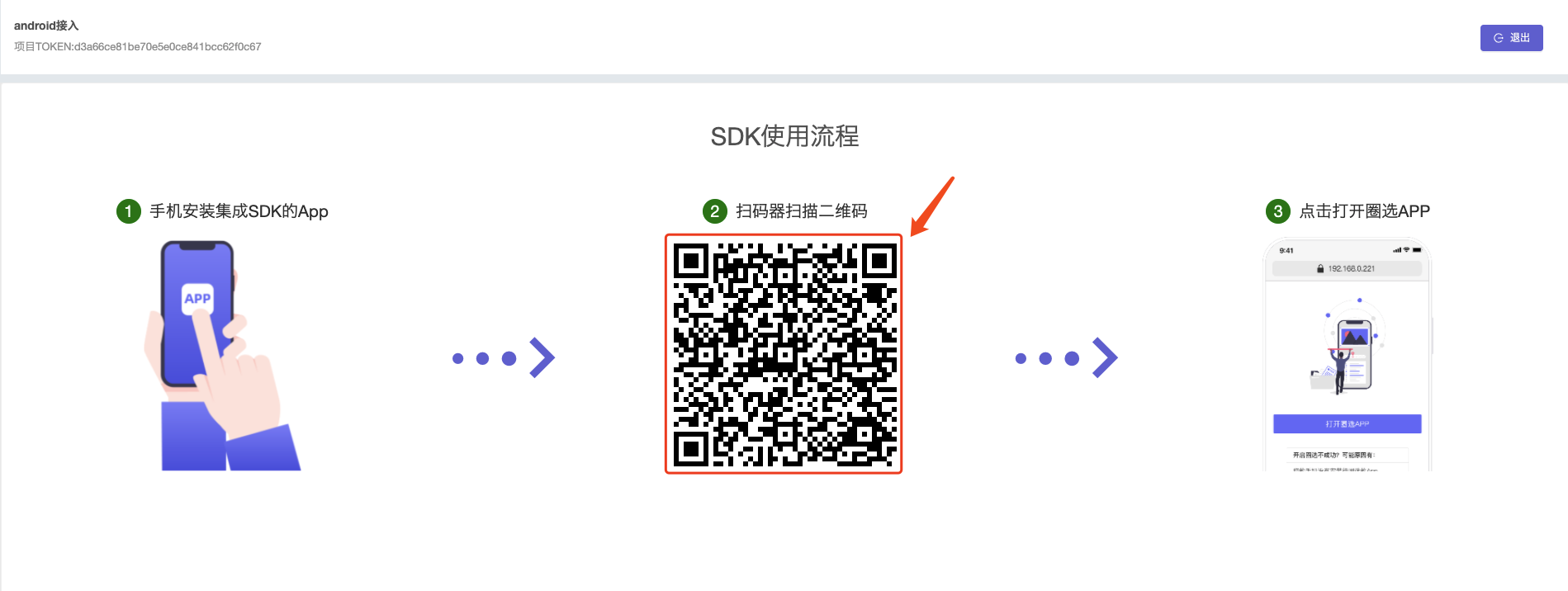
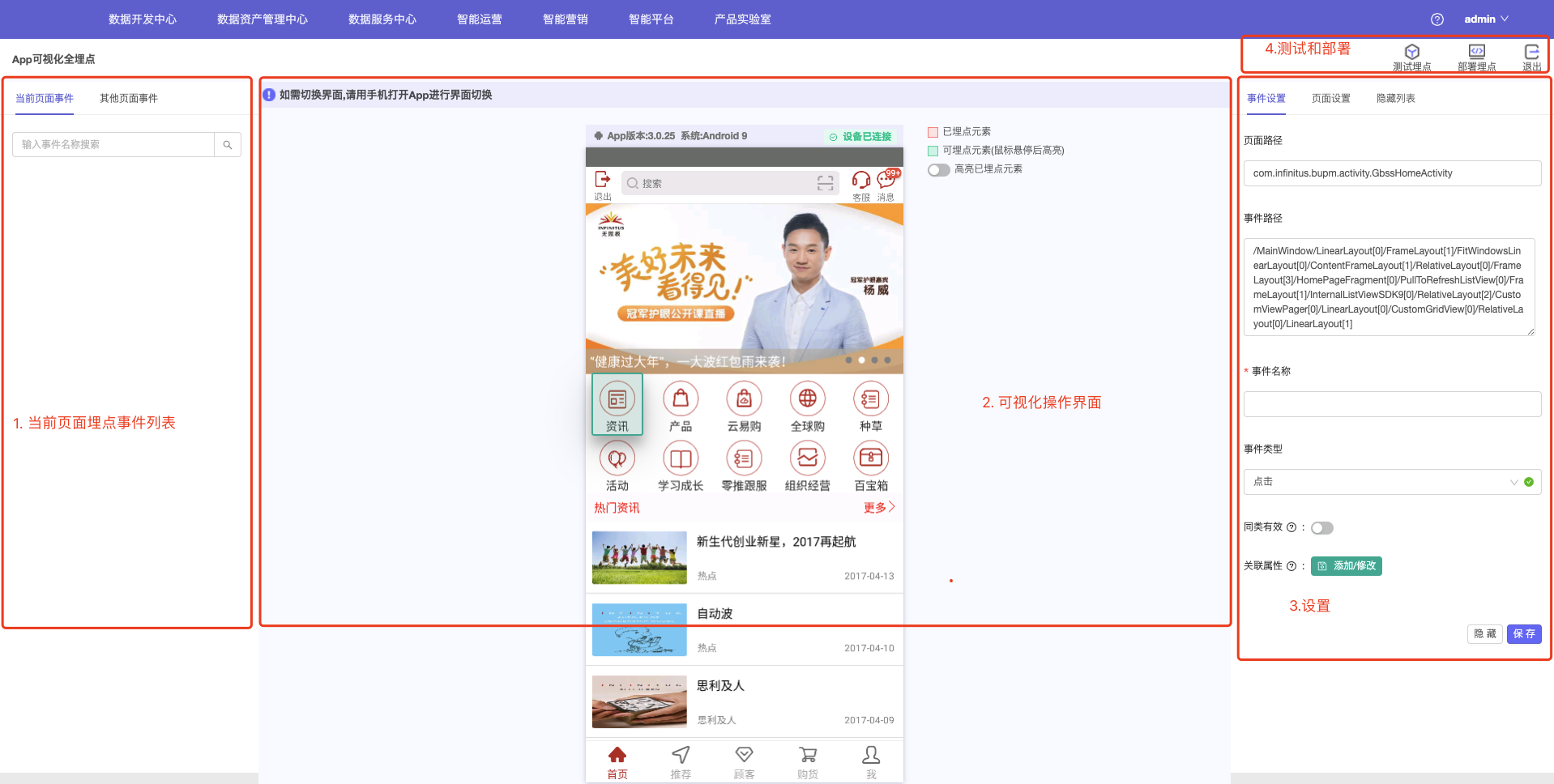
3.启动APP后,电脑上的界面也会自动转至APP可视化埋点界面。 主要由以下部分组成:
- 展示当前页面已埋点的事件列表和其他所有事件列表;
- 可视化操作界面:展示APP的实时界面,圈选埋点元素;
- 事件设置:对当前显示的页面进行埋点设置;页面设置:对当前页面设置名称;隐藏列表:显示被遮住控件的埋点列表;
- 埋点测试与发布按钮,退出埋点按钮。
埋点设置
原生页面元素埋点
在可视化操作界面上点选需要埋点的元素,右侧进行事件设置:
- 事件名称:埋点事件的名称,请使用辨识度较高的名称,便于今后查询;
- 同类有效:宫格列表等控件,圈选字控件,开启同类。
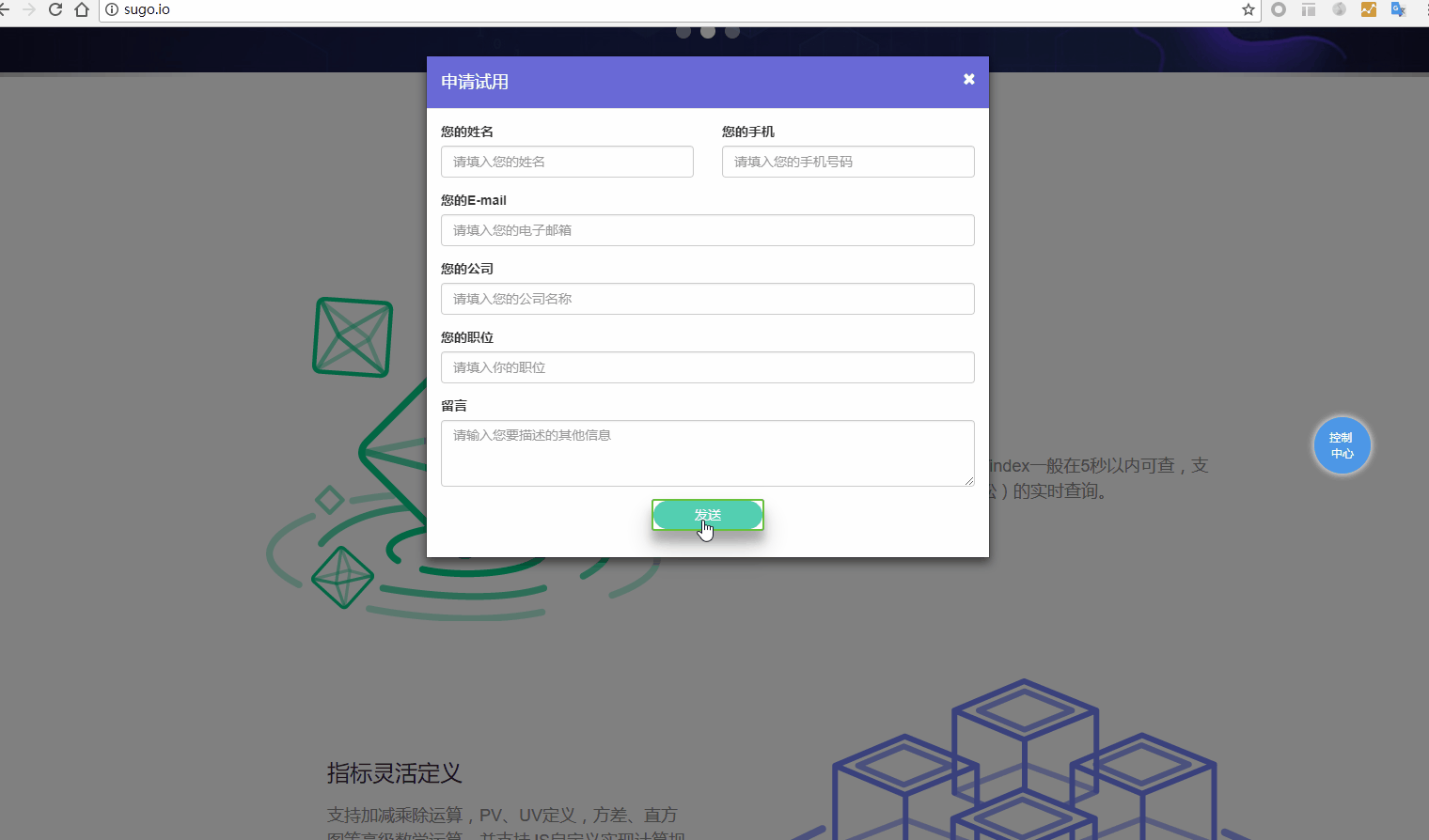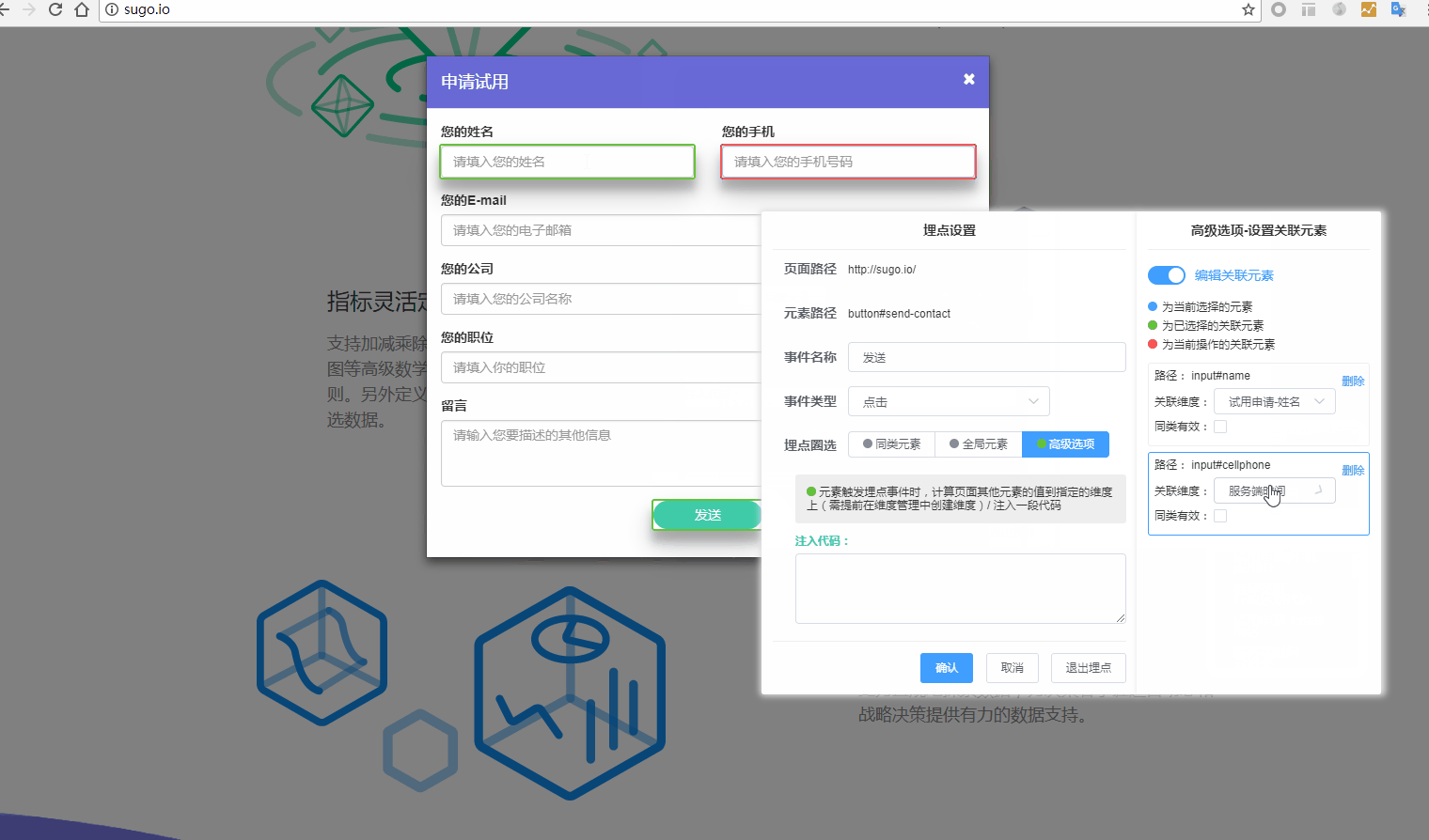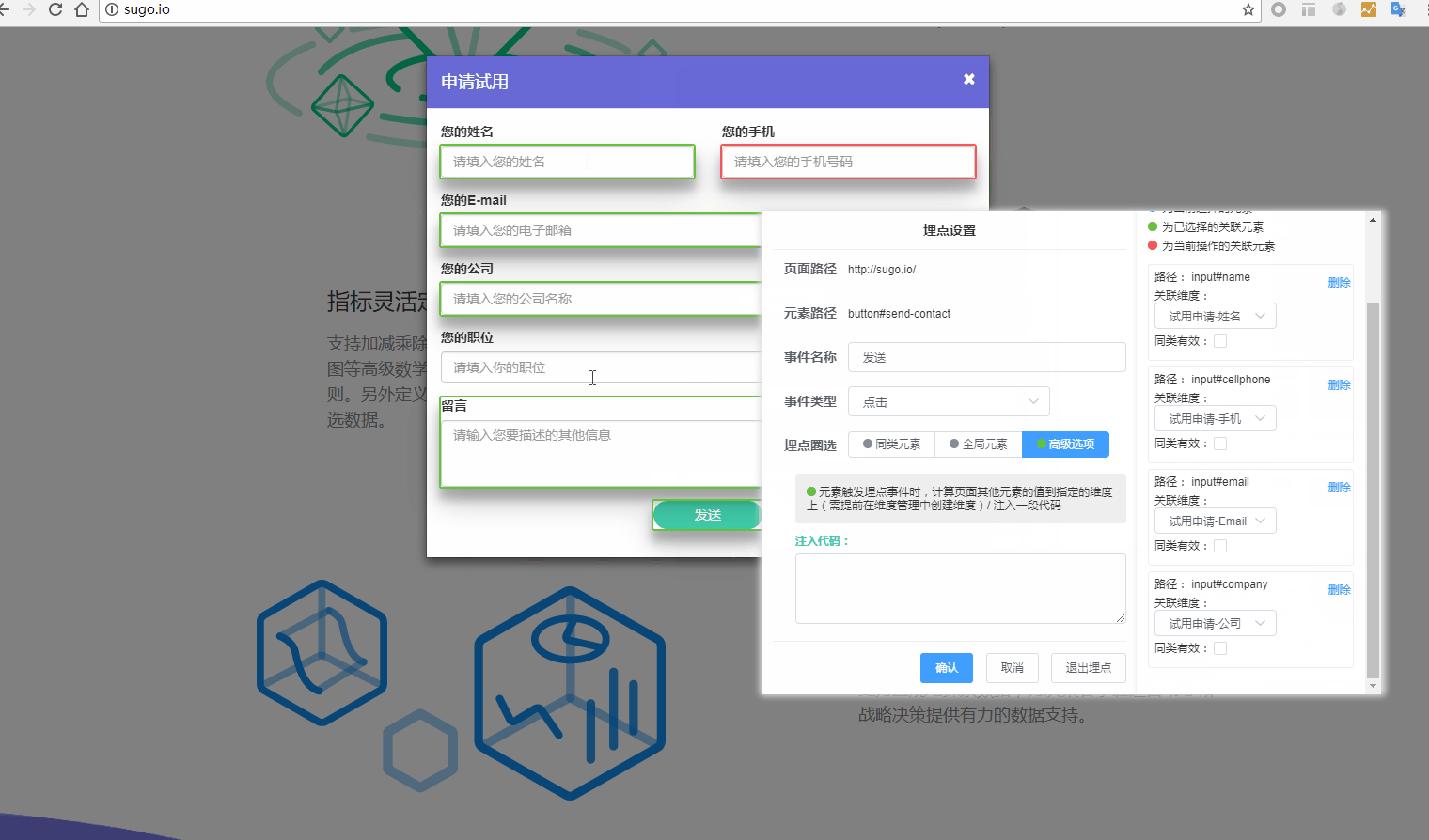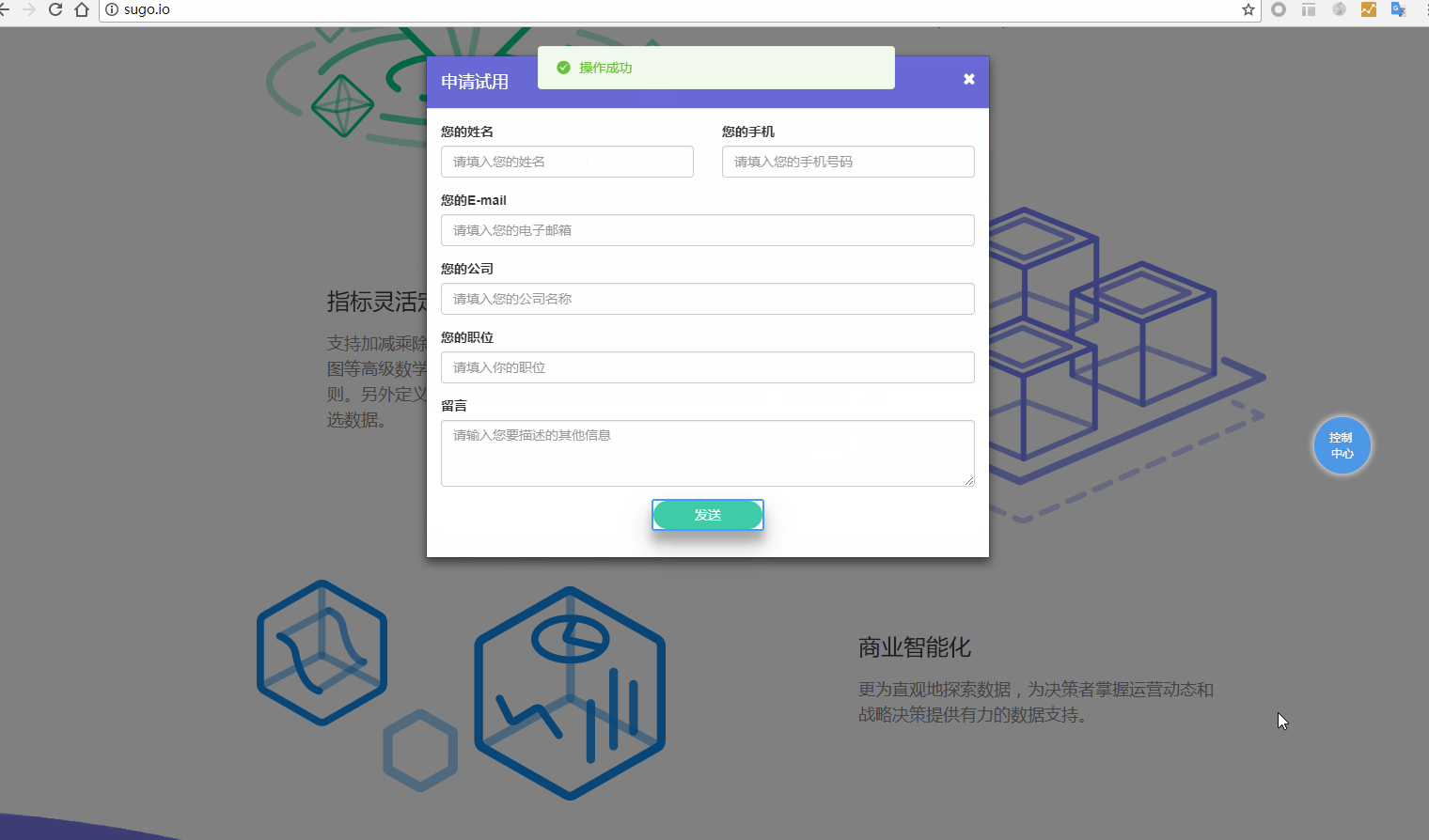
- 关联属性:在当前埋点事件触发时,将页面中某个或多个指定可视元素的文本上报至自定义维度字段(需要在维度管理中预先创建维度)
1.普通控件埋点操作,例如:
- ① 可视化区域圈选首页-搜索框。
- ② 右侧-事件设置-填写事件名称,并保存埋点。
- ③ 点击-测试埋点,测试埋点是否生效。

2.同类控件埋点操作,例如:
- ① 可视化区域圈选首页底部Tab
- ② 右侧-事件设置-填写事件名称和开启同类埋点(一般选择最后一层),并保存埋点。
- ③ 点击-测试埋点,测试同类埋点是否生效。

3.关联控件埋点操作,例如:
- ① 维度管理新建维度-按钮名称。
- ② 可视化区域圈选已埋点的控件,点击右侧-关联属性,再次回到可视化区域圈选此埋点需要关联的控件。
- ③ 点击-测试埋点,测试关联埋点是否生效。

H5页面元素埋点
在可视化操作界面上点选需要埋点的元素,右侧进行事件设置:
- 事件名称:埋点事件的名称,请使用辨识度较高的名称,便于今后查询;
- 同类有效:宫格列表等控件,圈选字控件,开启同类。
- 关联属性:在当前埋点事件触发时,将页面中某个或多个指定可视元素的文本上报至自定义维度字段(需要在维度管理中预先创建维度)
- 注入代码:支持js片段获取当前页面指定元素的值。
- 支持一端圈选两端生效。
1.普通控件埋点操作,例如:
- ① 右侧面板,页面路径切换到H5,可视化区域圈选H5-搜索框。
- ② 右侧-事件设置-填写事件名称,并保存埋点。
- ③ 点击-测试埋点,测试埋点是否生效。

2.同类控件埋点操作,例如:
- ① 右侧面板,页面路径切换到H5,可视化区域圈选H5-宫格业务。
- ② 右侧-事件设置-填写事件名称和开启同类埋点(一般选择最后一层),并保存埋点。
- ③ 点击-测试埋点,测试同类埋点是否生效。

3.关联控件埋点操作,例如:
- ① 维度管理新建维度-按钮名称。
- ② 可视化区域圈选已埋点的控件,点击右侧-关联属性,再次回到可视化区域圈选此埋点需要关联的控件。
③ 点击-测试埋点,测试关联埋点是否生效。

4.高级特性-注入js代码,例如:
- ① 可视化区域圈选H5-加入购物车,右侧-事件设置添加名称,
- ② 注入代码处填写js片段,获取想要的页面隐藏元素值。
③ 点击-测试埋点,测试埋点是否生效,并查看注入的js是否获取到值。
var hidden_ele = document.getElementById("eventdataid"); //通过id获取隐藏元素 var eventdataid = hidden_ele.getAttribute("value") // 获取隐藏元素值 return { AAAID : eventdataid} //里写的是一个函数内容,最终返回为json对象的自定义属性。
页面设置
1.设置当前显示页面的名称,例如:
- ① 设置首页名称和搜索页面名称
- ② 切换到右侧面板-页面设置,填写页面名称。
③ 点击-测试埋点,测试页面埋点是否生效。

埋点事件列表
可视化区域左侧面板事件列表:
- 1.当前页面事件tab,显示当前页面的所有埋点。
- 2.其他页面事件tab,显示所有的埋点。
- 3.列表操作,支持编辑删除、查看埋点信息。

可视化维护
- 1.不同版本埋点列表维护
- 2.版本级别和全局配置维护
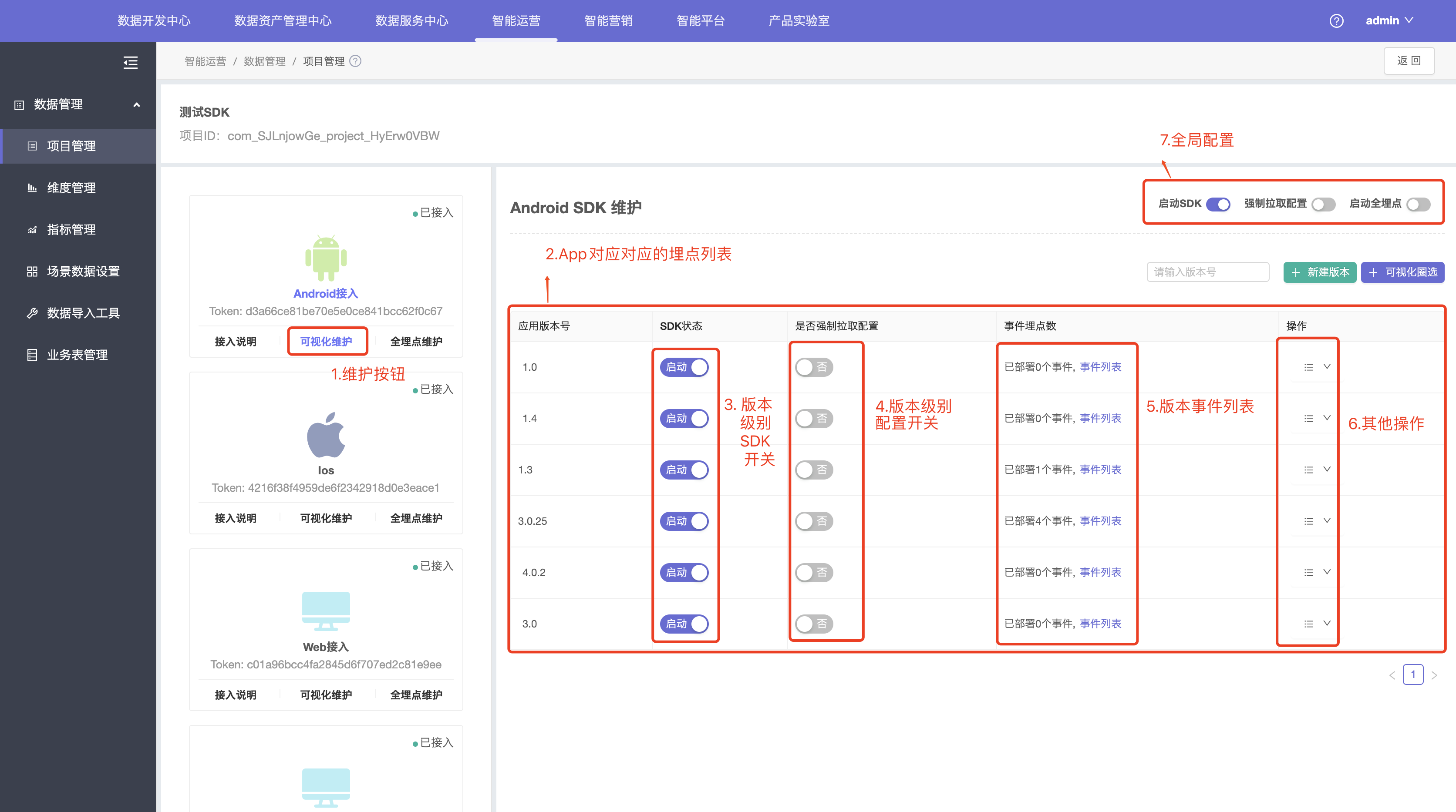
全埋点维护
1.SDK默认全埋点是关闭的,需要自行开启:
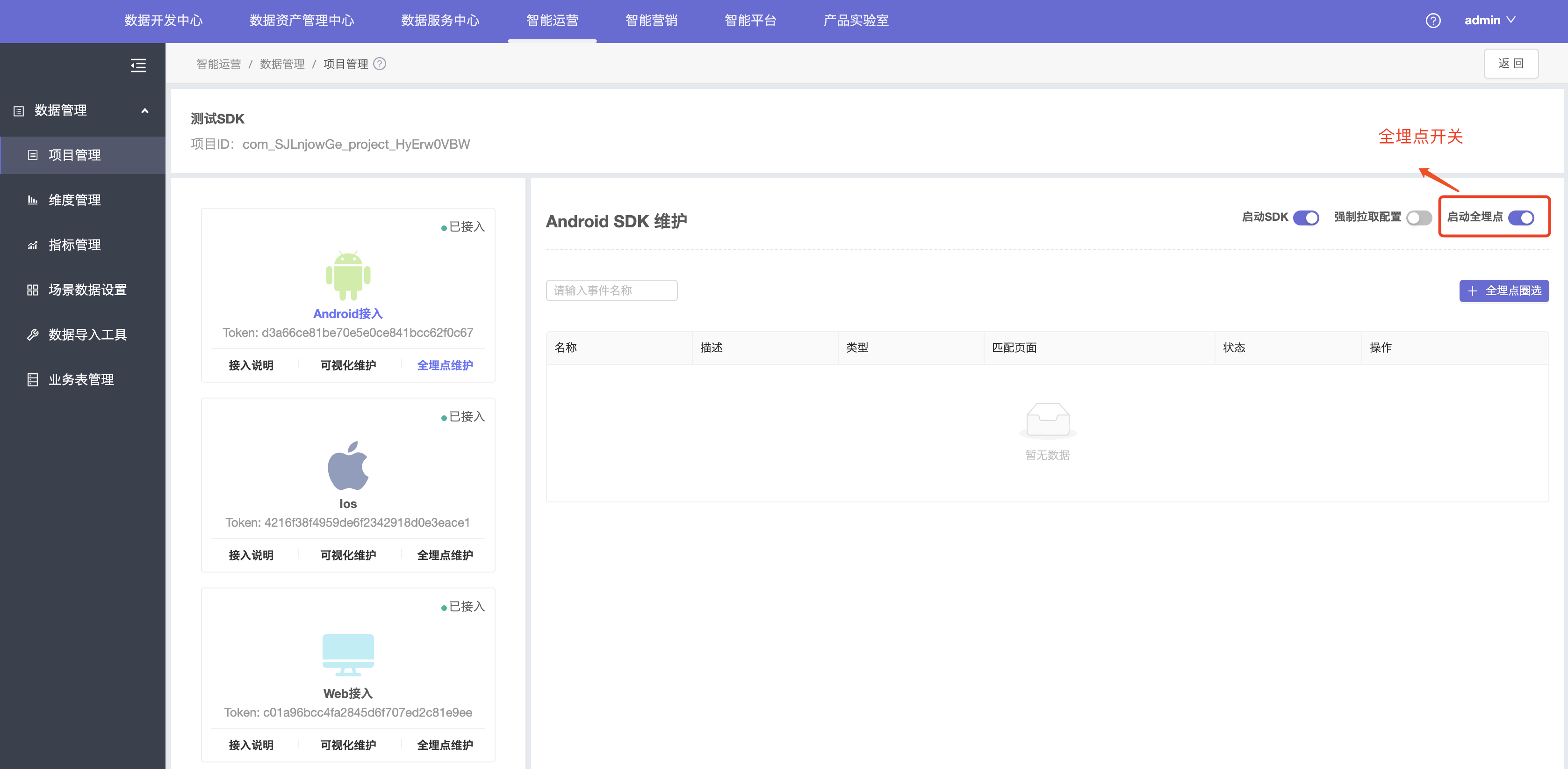
2.点击全埋点圈选按钮,进入可视化页面。
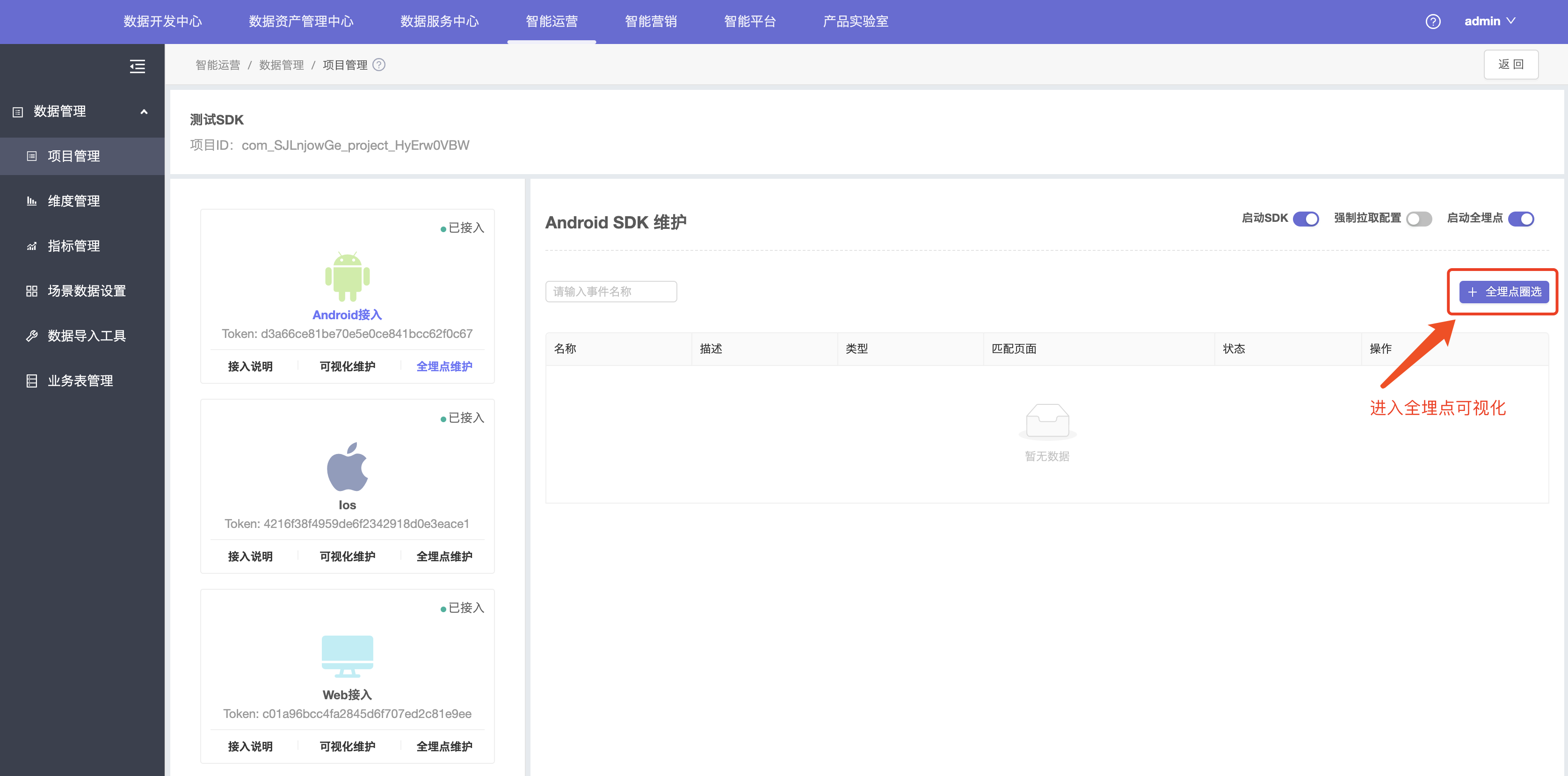
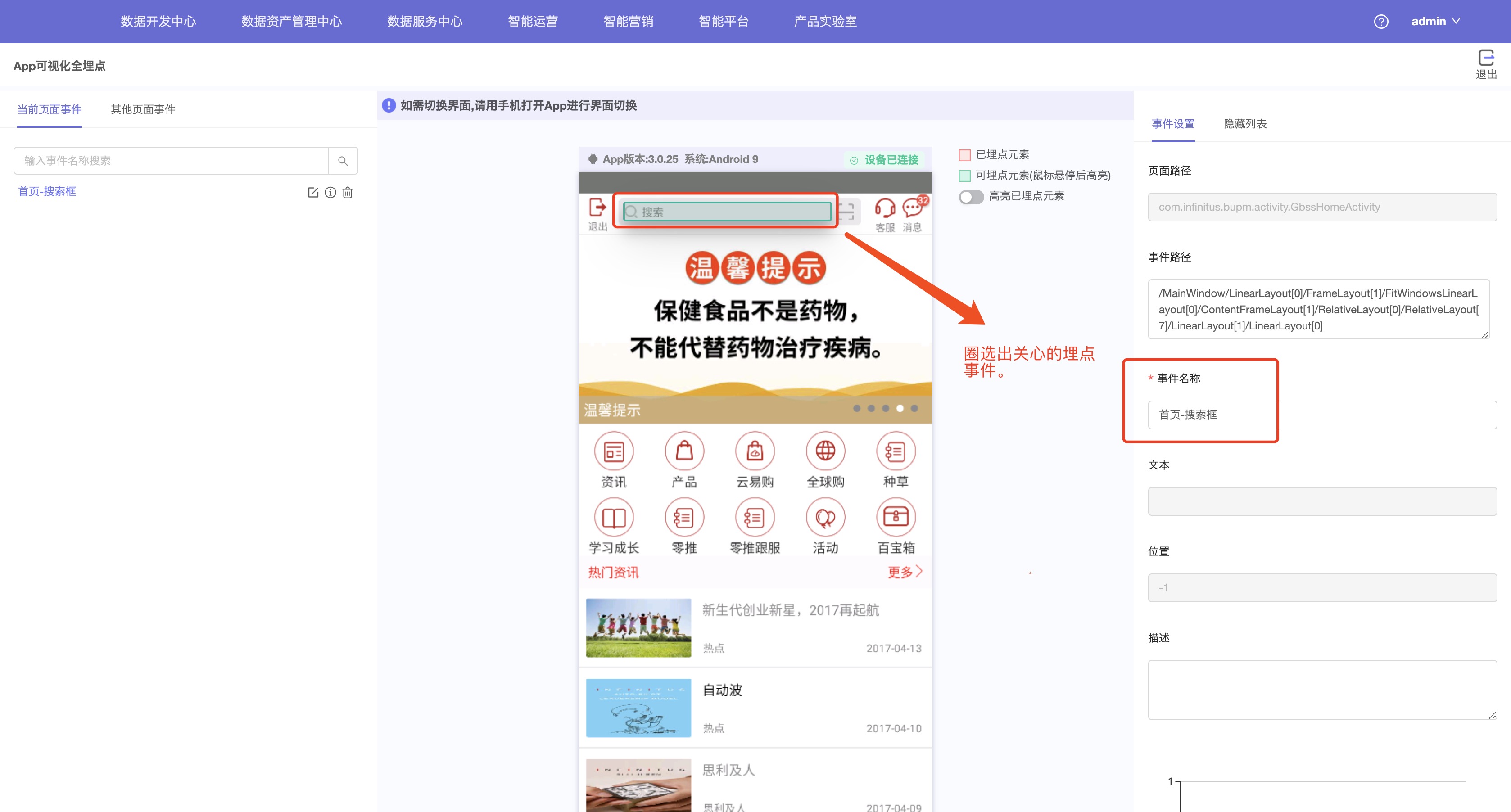
3.圈选关心的埋点数据并保存。
4.退出返回全埋点维护页面,查看过滤的全埋点列表。
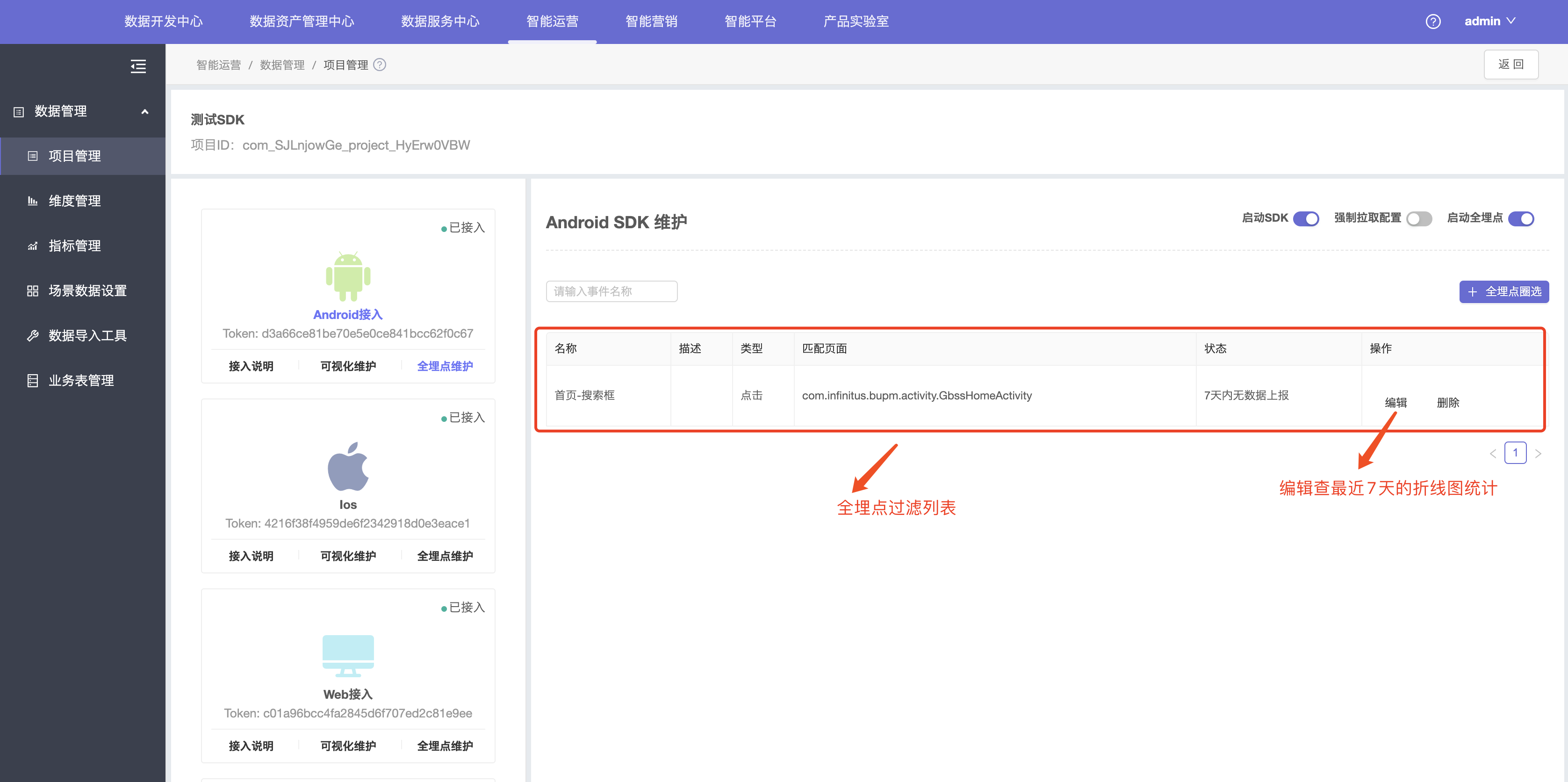
5.点击编辑,查看埋点信息机最近7天的折线统计图。
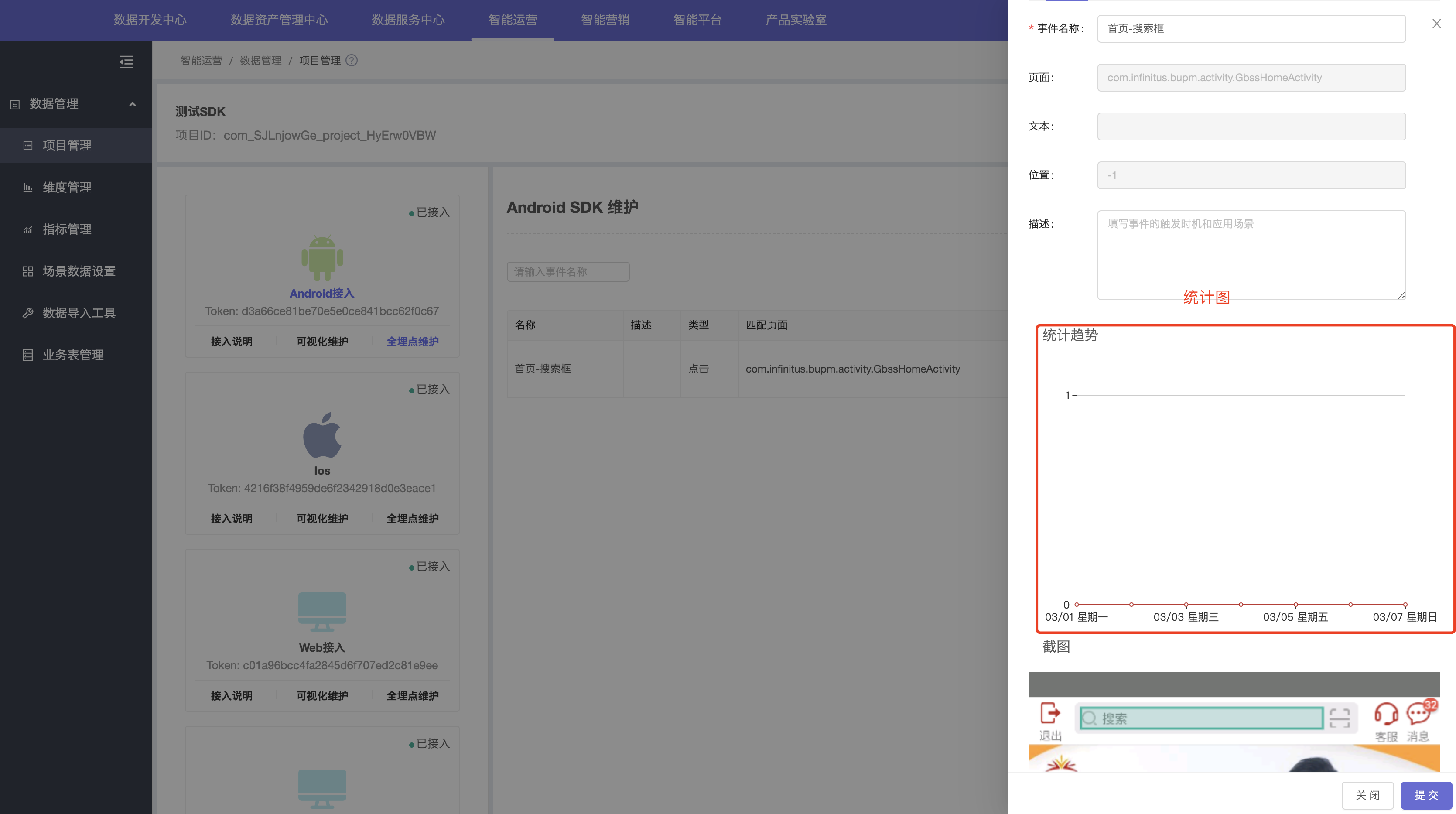
Web可视化全埋点
1.点击接入说明按钮,按文档进行接入。
也可以可以参见开发者文档部分。
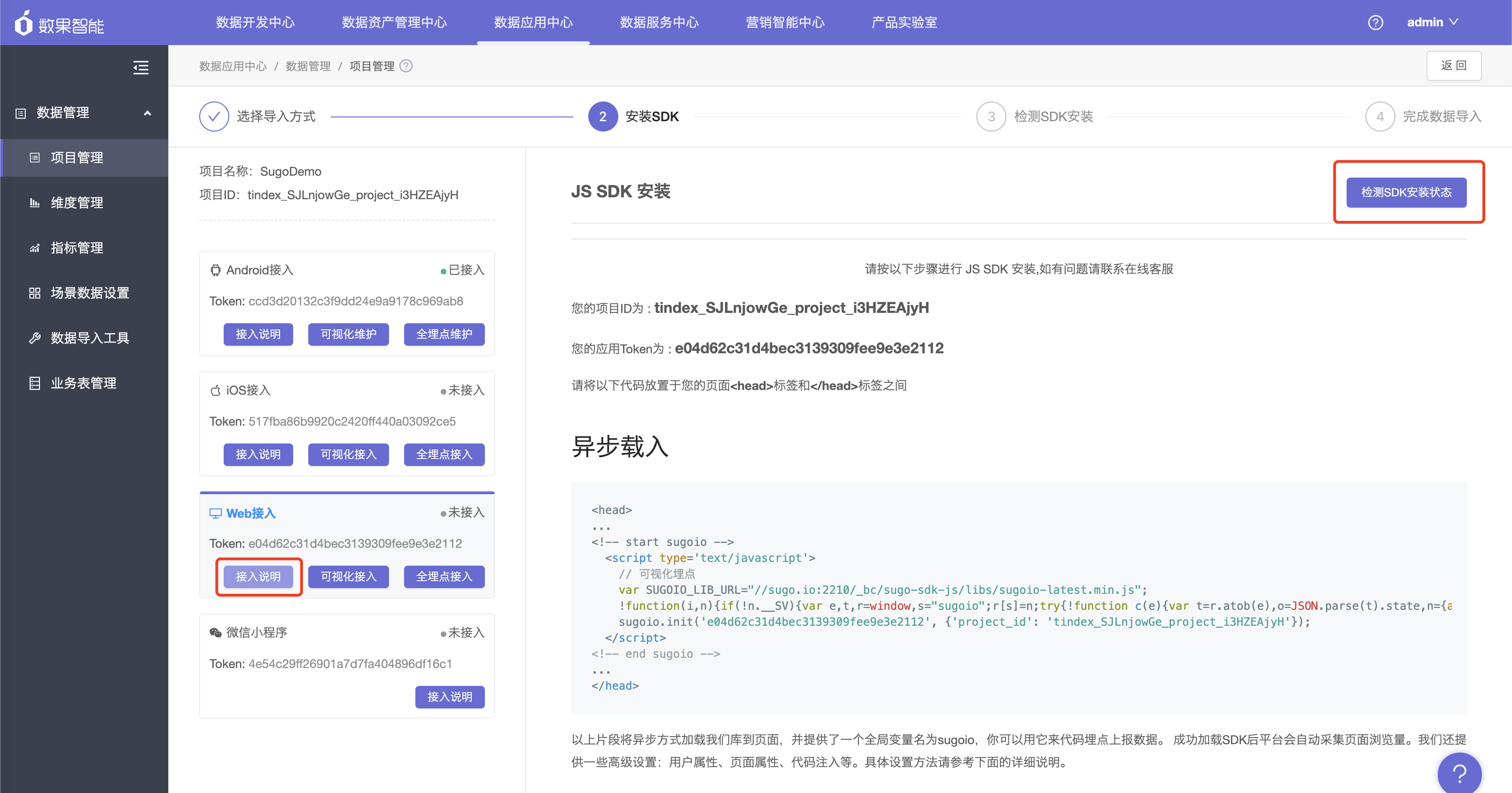
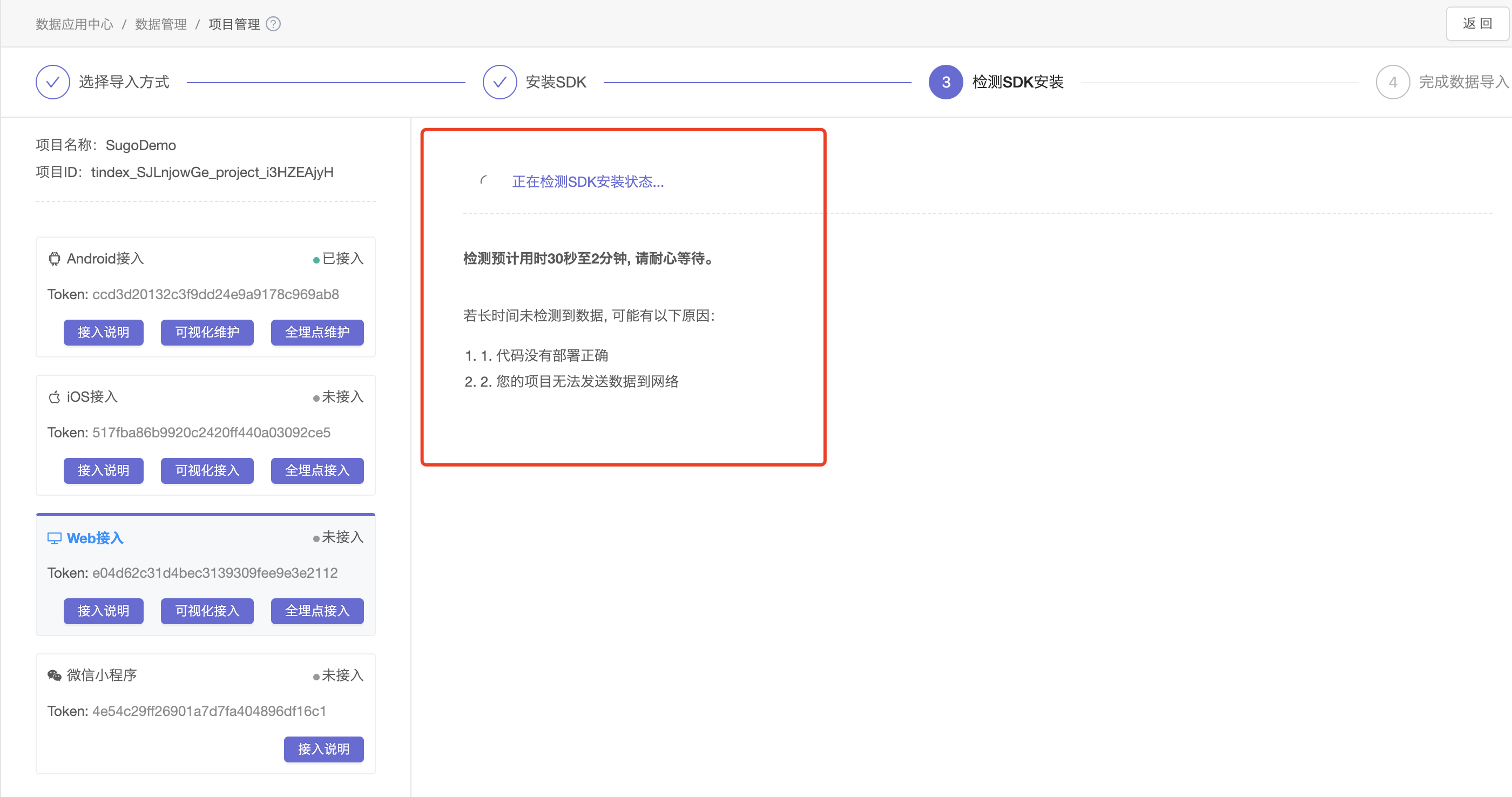
2.SDK检测可能需要30秒至2分钟不等,若检测失败,可按照页面提示进行排查。
当SDK安装检测成功,即可开始可视化埋点。
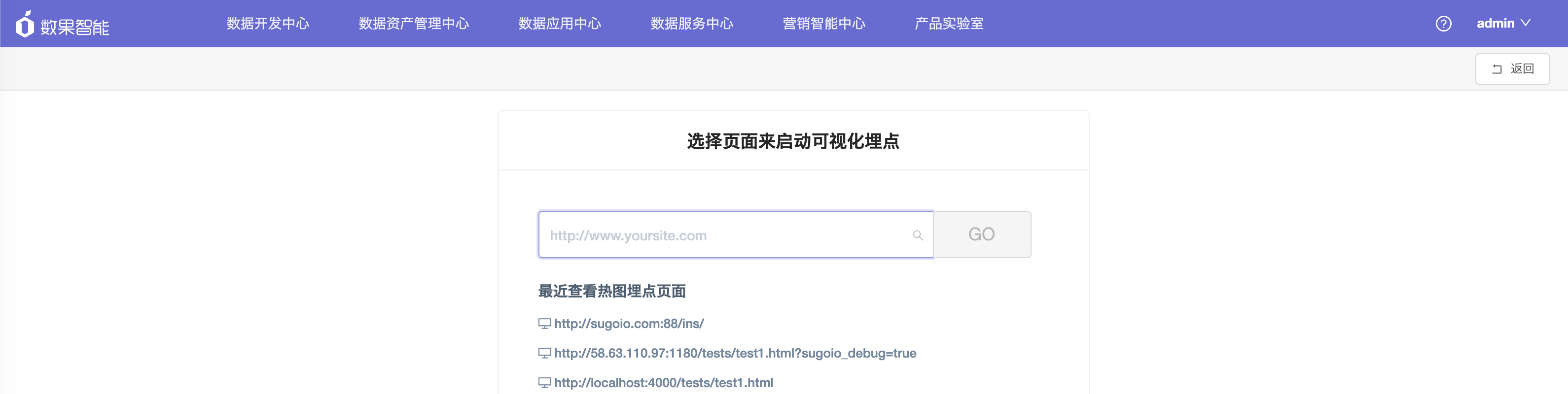
3.首次进行埋点时,需输入项目首页的地址。
4.进入埋点界面后我们可以看到项目页面本身,以及埋点工具按钮。埋点工具按钮可以任意拖动位置。鼠标悬停埋点工具按钮时,将出现埋点工具菜单:页面设置、创建埋点、埋点列表、页面分类、部署埋点、退出。
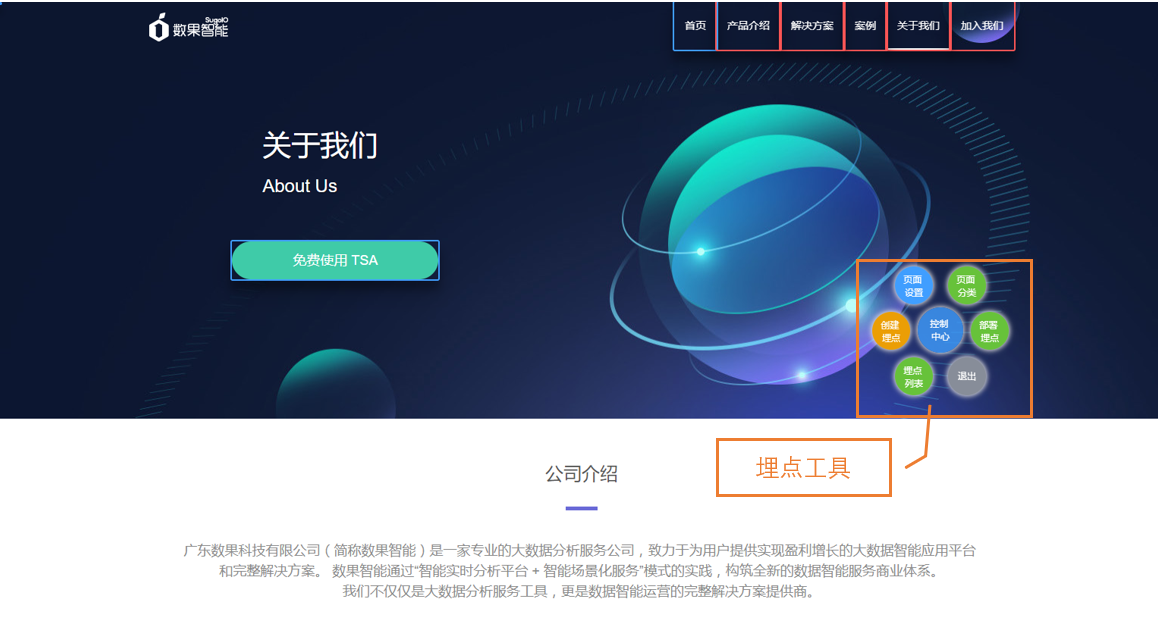
页面设置
1.页面设置功能主要用于设置页面名称的上报规则。
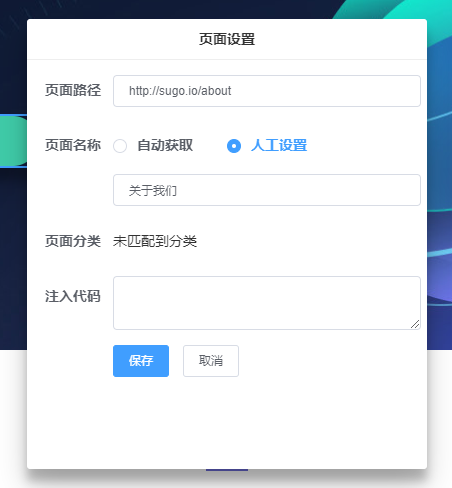
页面路径:默认为当前页面的URL,即表达下面的页面名称等设置对此URL生效。页面路径支持通配符“*”,当使用通配符时,将会让本页面的埋点事件对所有符合页面路径的页面有效。
页面名称:分为自动获取和人工设置两种上报方式。自动获取是指数据上报时,自动获取页面head标签里,title标签中的内容作为页面名称,当title发生修改时,无需重新设置;人工设置是指人工输入要上报的固定页面名称。
页面分类:显示当前页面所匹配的页面分类名称,详见上文APP中的页面分类功能说明。
- 注入代码:根据需要填入js代码,可在页面载入时抓取页面指定内容,并上报至指定字段。详细说明可参考上文APP埋点部分的注入代码。
创建埋点
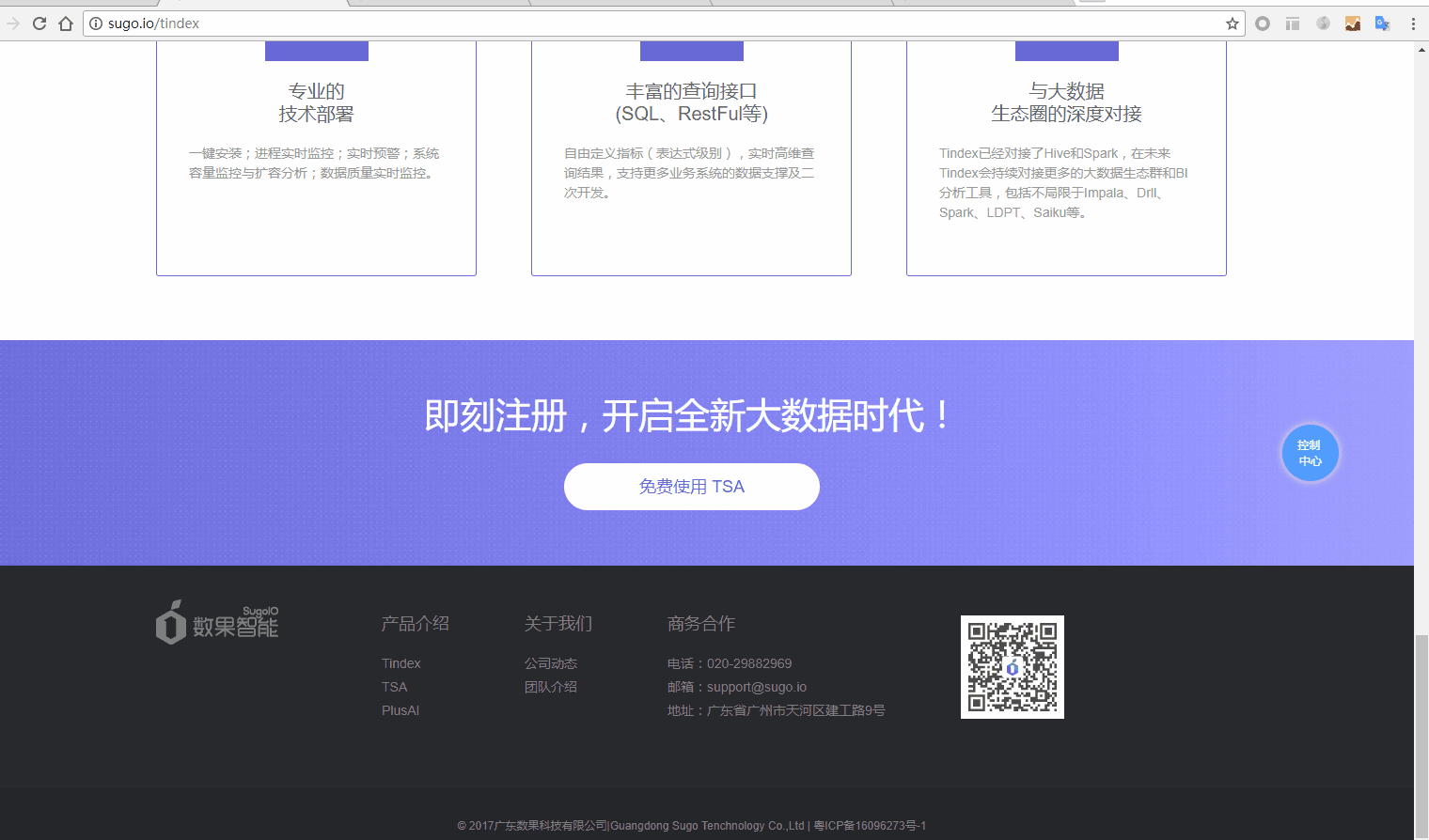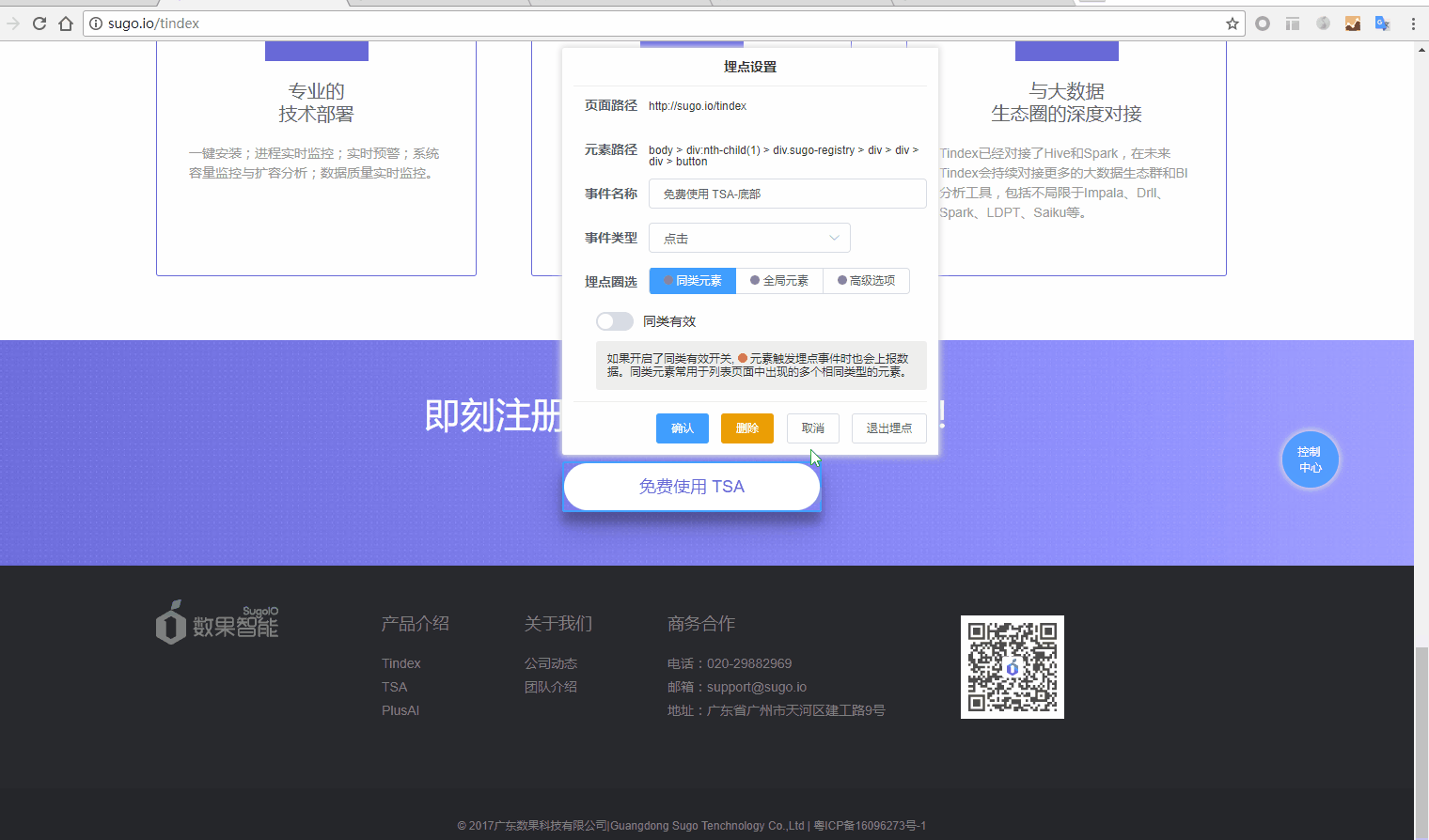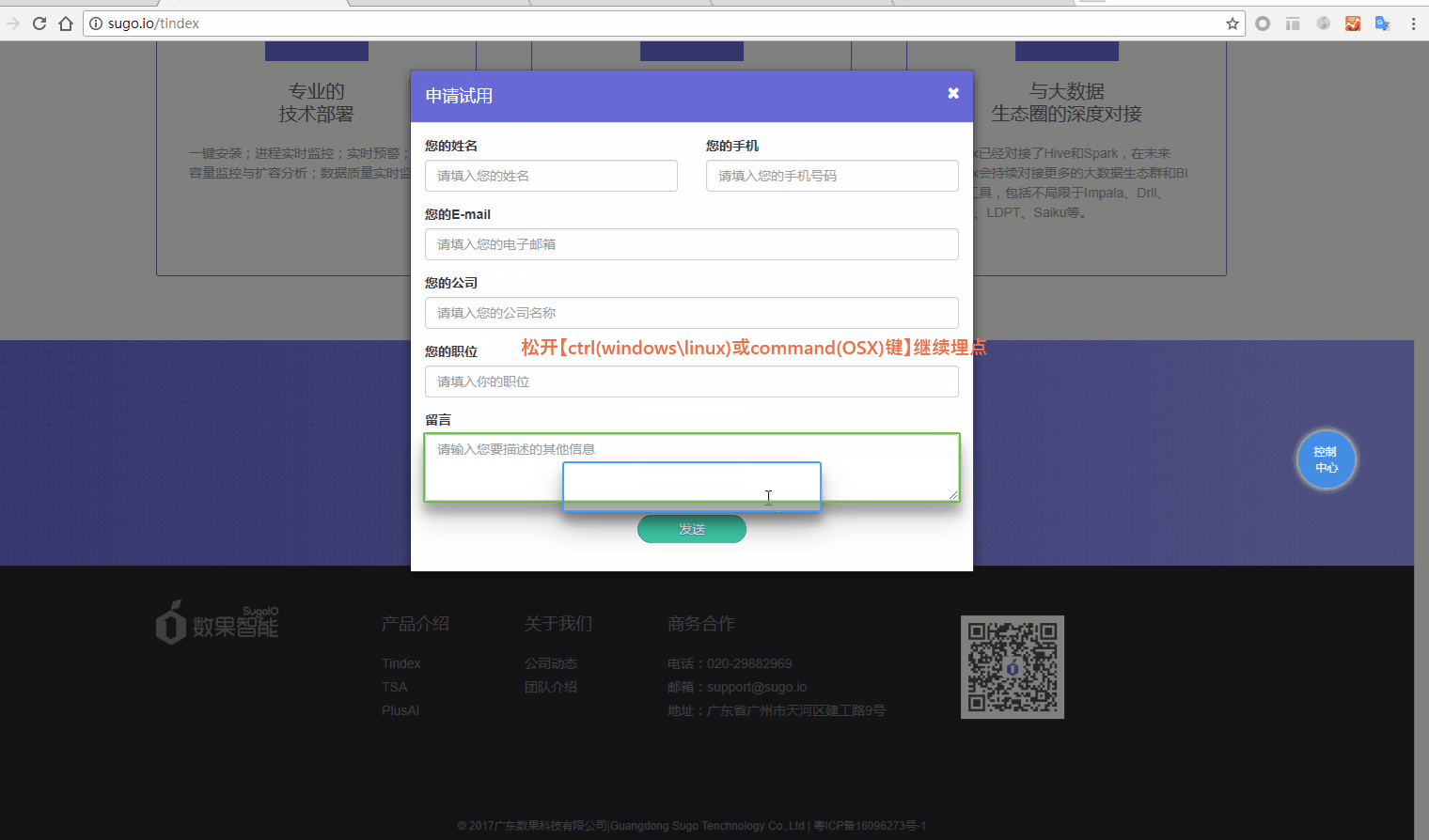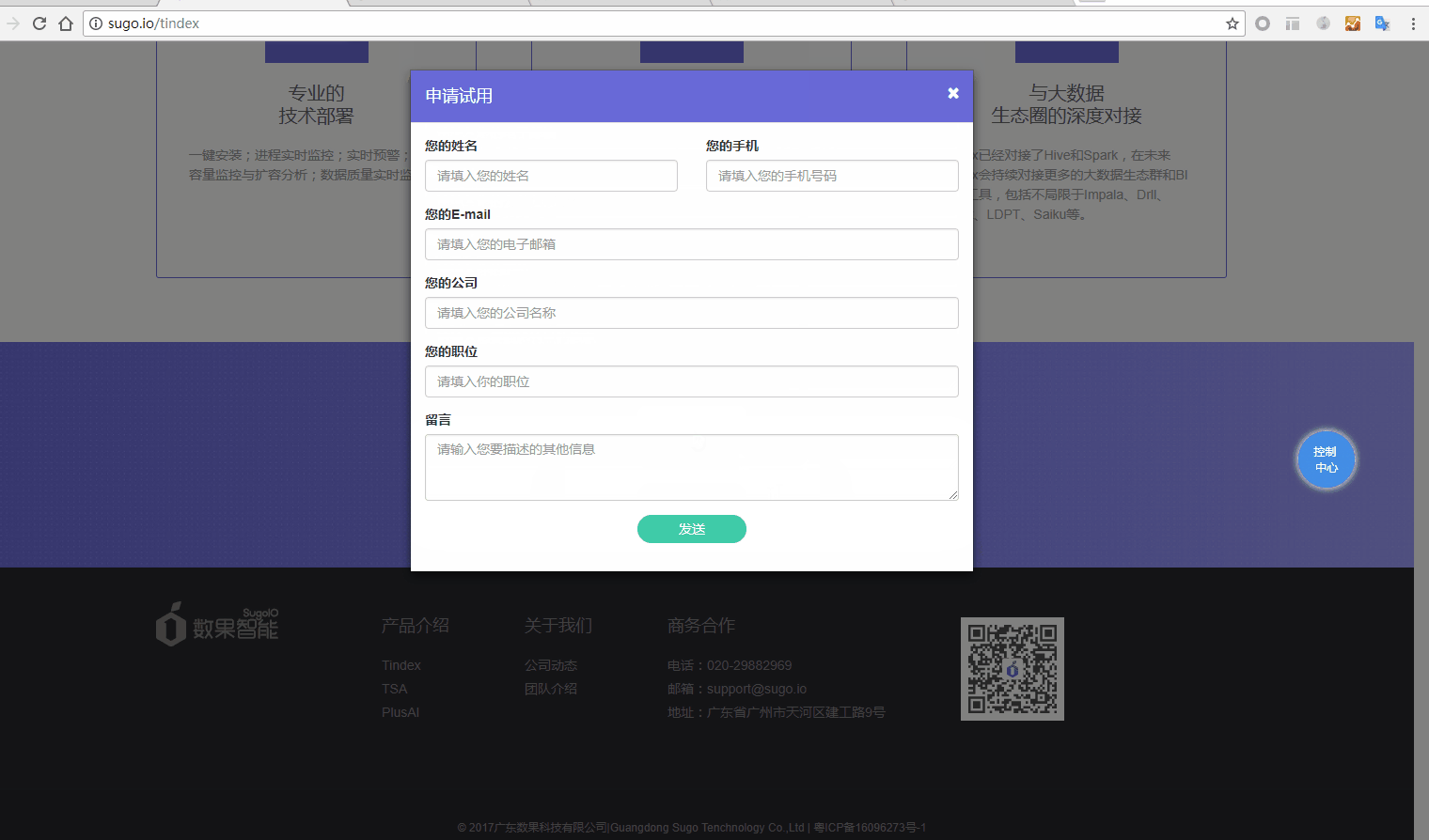
1.点击创建埋点按钮后,页面将进入埋点状态,此时页面将不可跳转,鼠标悬停在页面元素时会显示绿色的圈选框。当圈选需要埋点的元素后,点击鼠标左键即可弹出埋点设置菜单。

2.我们在埋点设置菜单中完成对圈选元素的埋点事件配置。
- 1.页面路径:取自页面设置中的页面路径,若页面设置的页面路径发生修改,此处会相应变化。上面图中页面路径带有通配符,意味着本事件将对所有符合页面路径规则的页面生效。
- 2.元素路径:当前圈选的页面元素的路径。
- 3.事件名称:为本事件输入名称,此名称将会被上报,在进行数据分析时使用。
- 4.事件类型:用于设置事件触发上报的条件。点击,当元素被点击时触发事件上报;改变,当元素内容改变时触发事件上报(例如下拉菜单选项改变);对焦,当元素获取焦点时触发事件上报(例如光标点入一个输入框)。
- 5.同类有效:设置此埋点是否对页面中的同类元素一并生效。同类元素通过元素的全量路径进行判别,可任意定制元素的父级影响范围。原始埋点元素为蓝色,同类元素为红色。
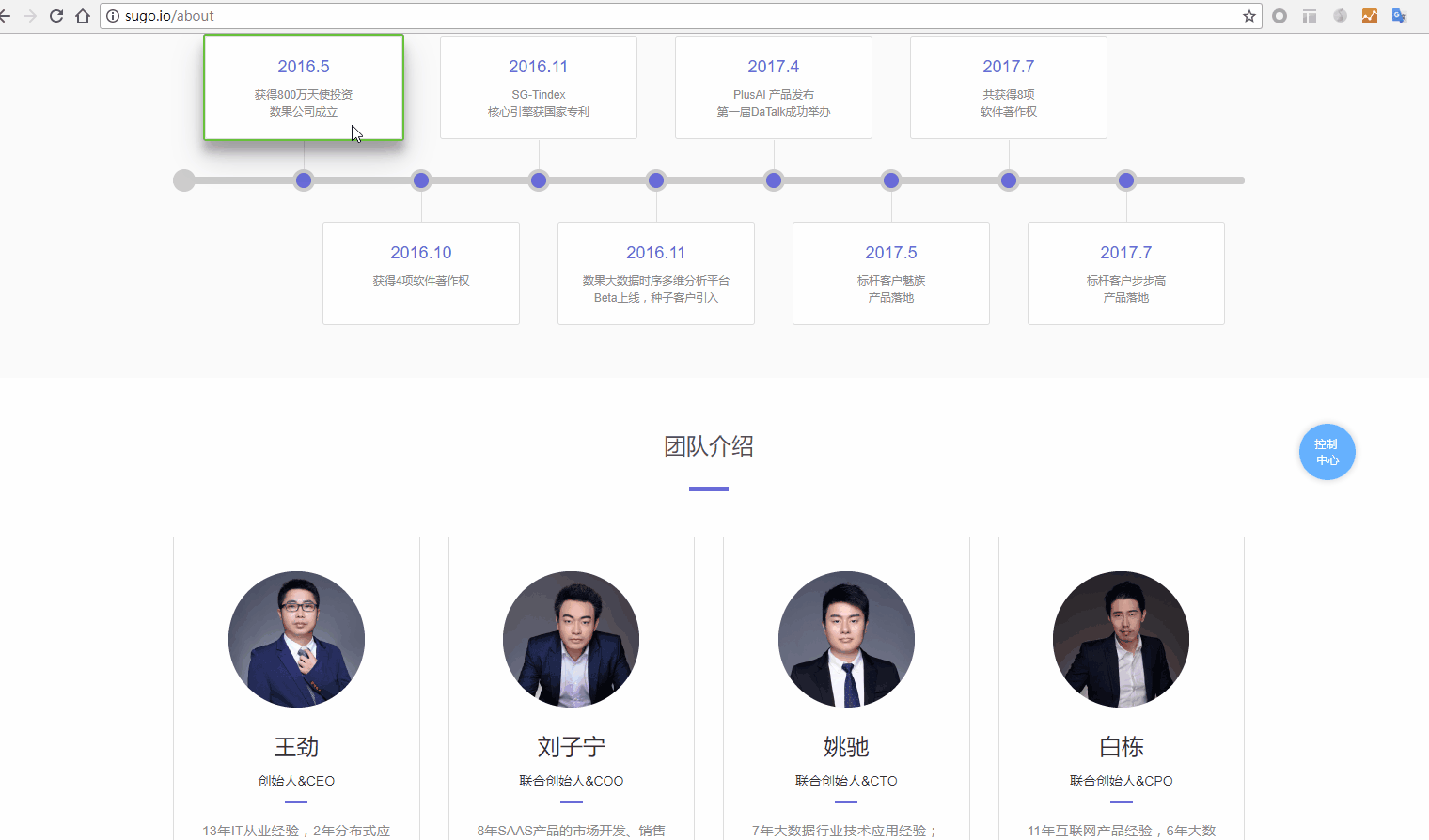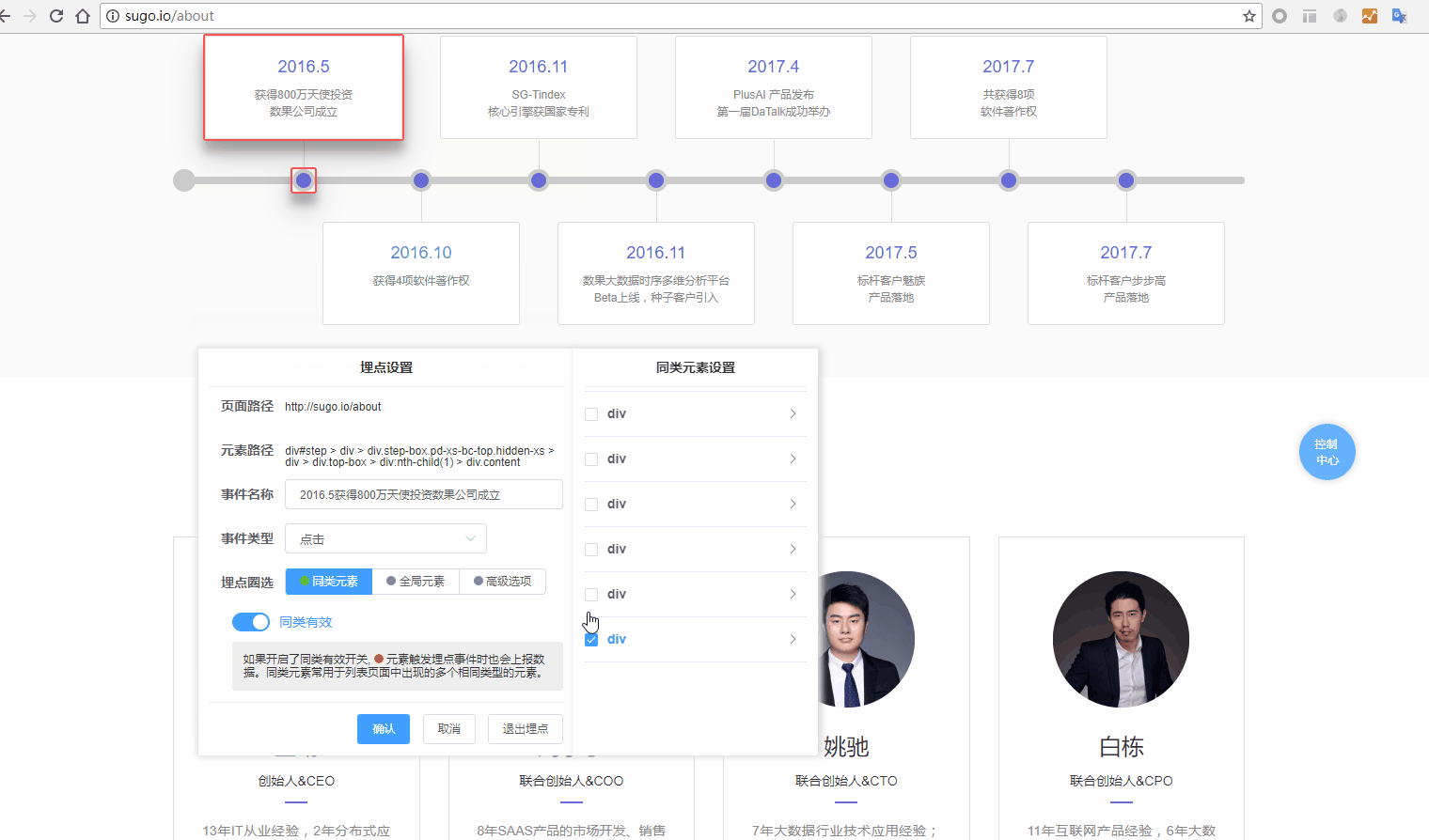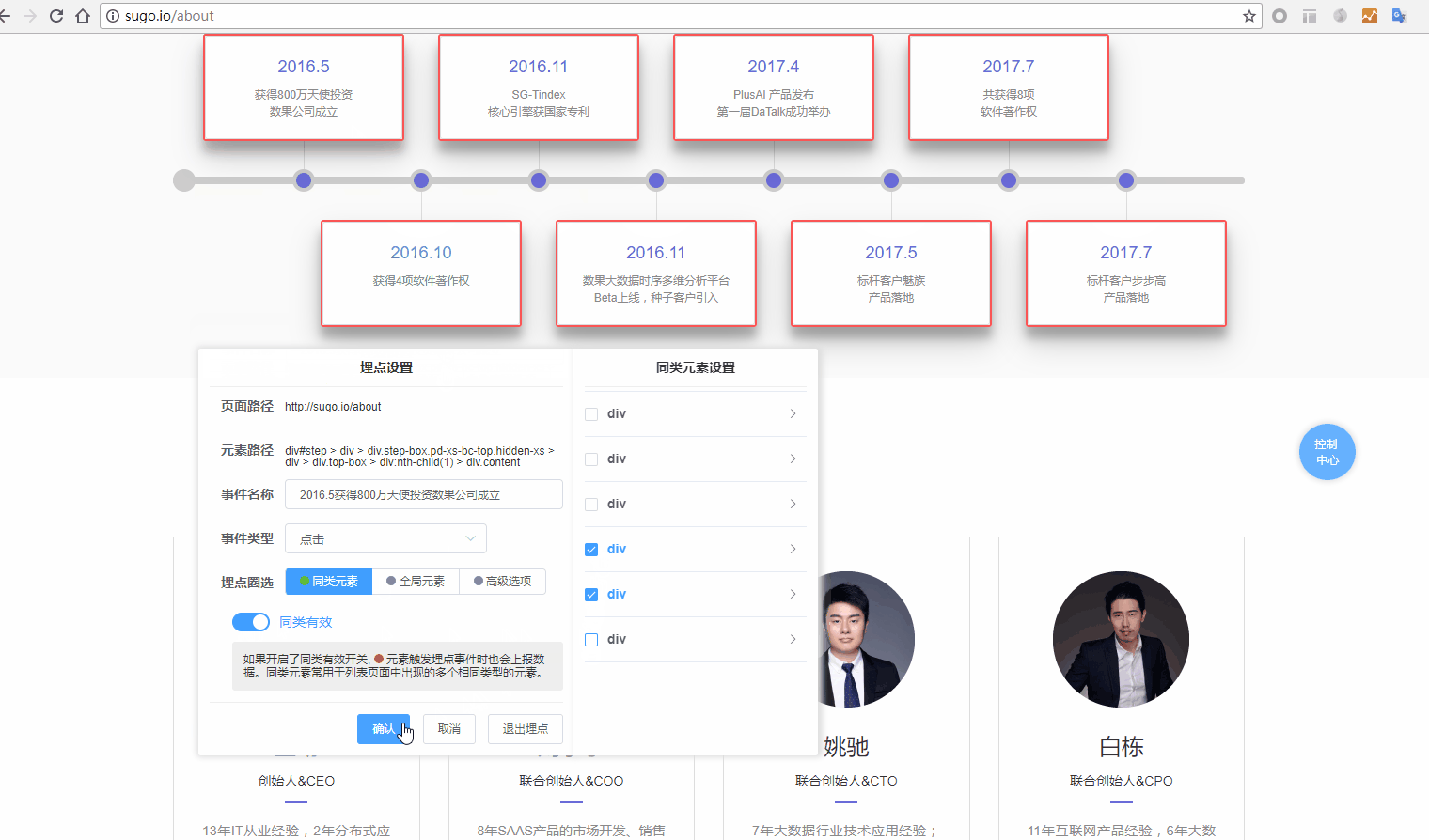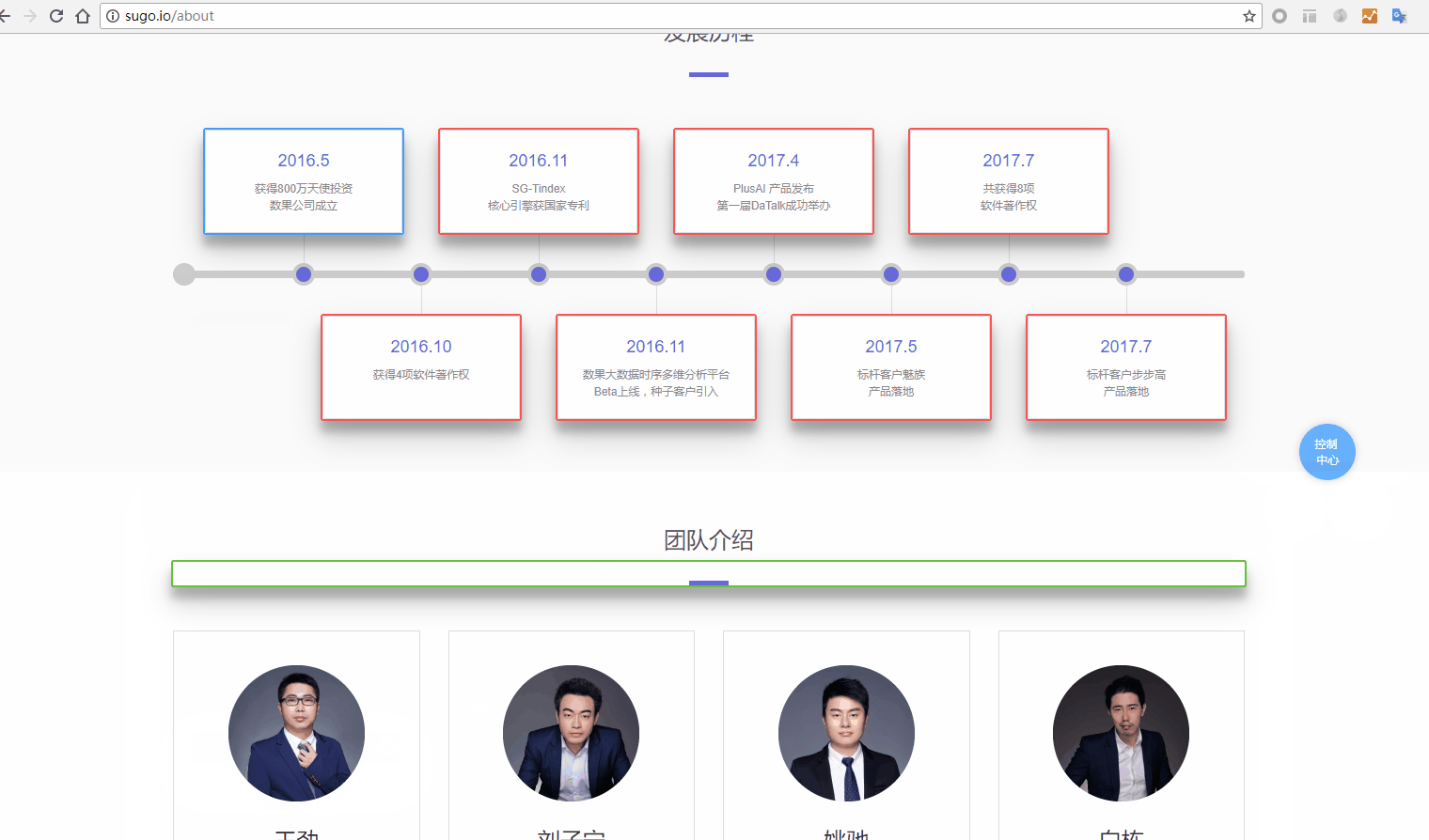
当然,如果简单的div不能满足同类的需求,还能展开每一层的div对其class/id,甚至是自定义添加的标识进行设置。
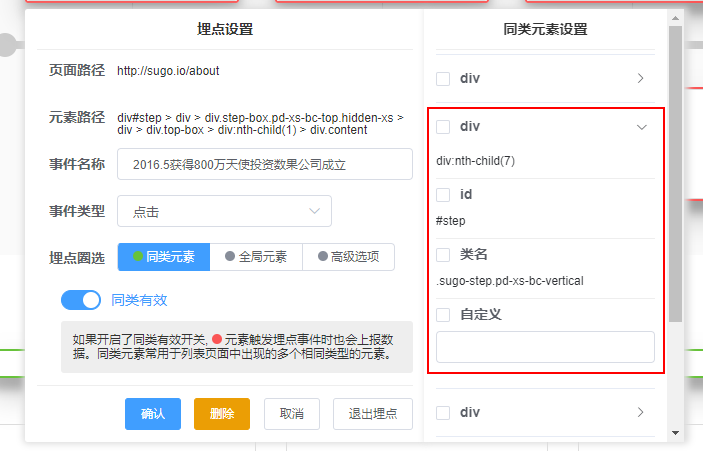
- 6.全局有效:设置此埋点是否对整个网站内的同一全局元素一并生效。全局元素通过元素路径进行判别,例如几乎贯穿全站的主导航栏,通常具有相同的元素路径,无论它位于哪个页面,都可视为同一个全局元素。
7.高级选项-上报数据:在当前埋点事件触发时,将页面中某个或多个指定可视元素的文本上报至自定义维度字段(需要在维度管理中预先创建维度);
8.高级选项-注入代码:根据需要填入js代码,可在页面载入时抓取页面指定内容,并上报至指定字段。详细说明可参考上文APP埋点部分的注入代码。
埋点小技巧-恢复原始点击事件
在进入创建埋点的状态后,无法点击按钮的原始事件就不能对事件的弹窗进行埋点。这时候只需要按住ctrl(windows\linux)或command(OSX)键,再点击按钮即可触发原始的事件。这时候松开按键后就回到埋点的状态,就能对事件的弹窗进行埋点操作了。
已创建完毕的埋点事件会在页面中用色框进行标记。创建完毕的事件并不会直接生效,需要点击“部署事件”按钮,进行部署之后才会发挥作用。 已经创建的事件或完成的修改,即使不进行部署也都已保存,下次进入埋点页面可延续上次的工作。
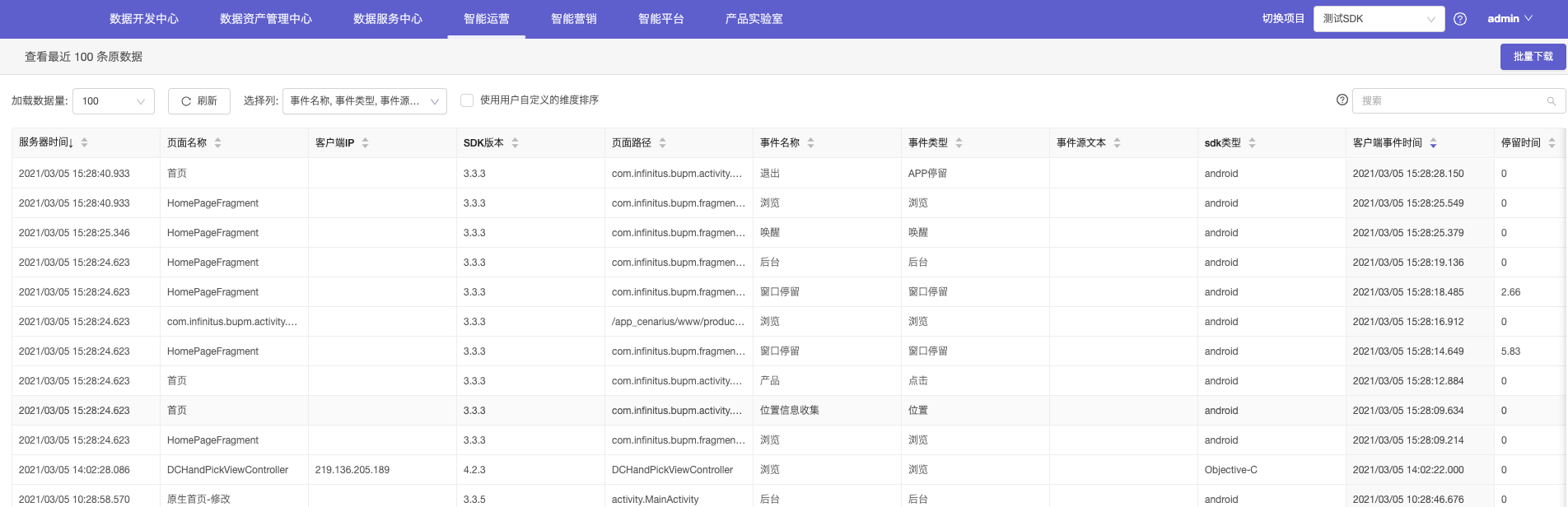
查看源数据
1.点击右侧按钮,查看数据/下载
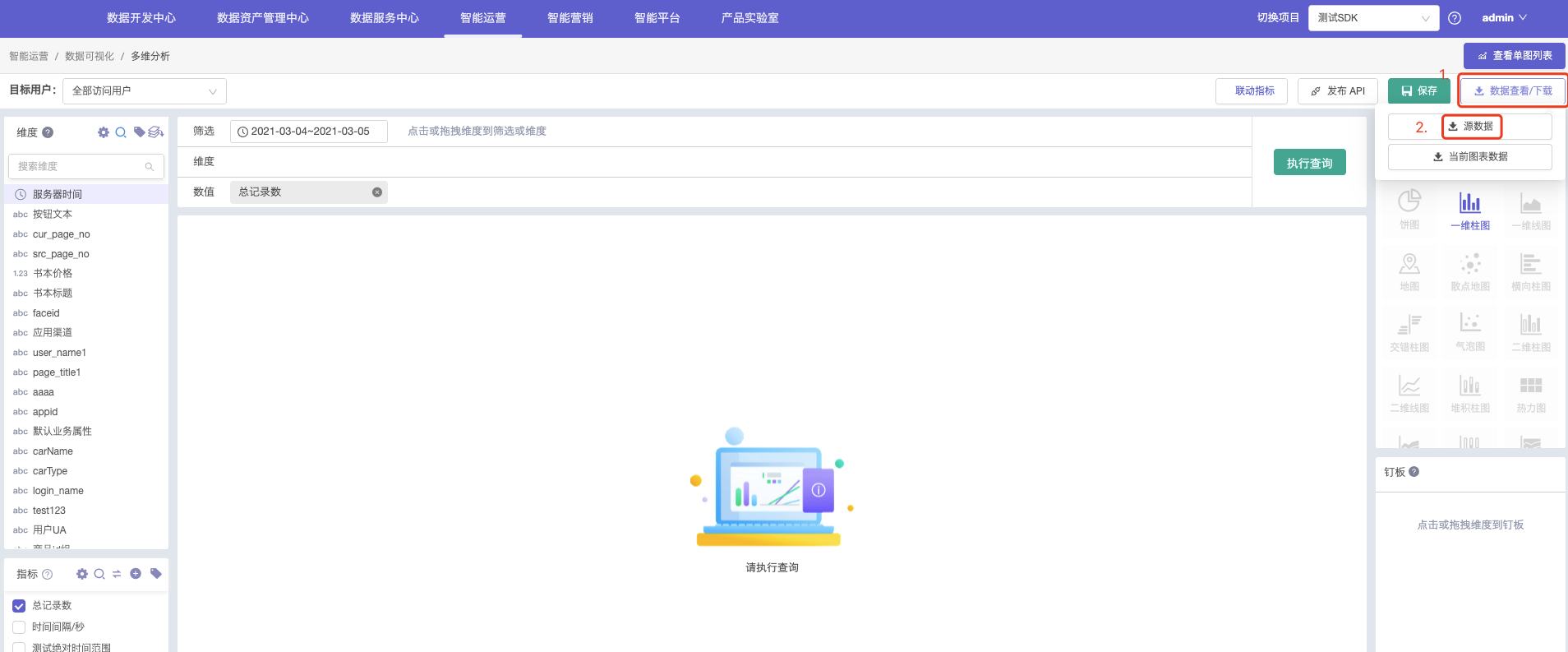
2.源数据展示。
文件导入
1.文件导入主要是用于快速接入小规模数据,用以做诸如活动的临时数据分析和储存,目前文件导入支持CSV文件(UTF-8编码),未来将提供更多文件格式的支持。 为保证性能与可靠性,若需导入大量数据,请使用我们提供的数据导入工具。
2.上传文件时,请确保CSV文件编码为UTF-8。同时,文件首行将判定为数据列标题,必须是英文或字母或下划线组成,不能以数字开头,不能包含中文,长度为2-50字节。
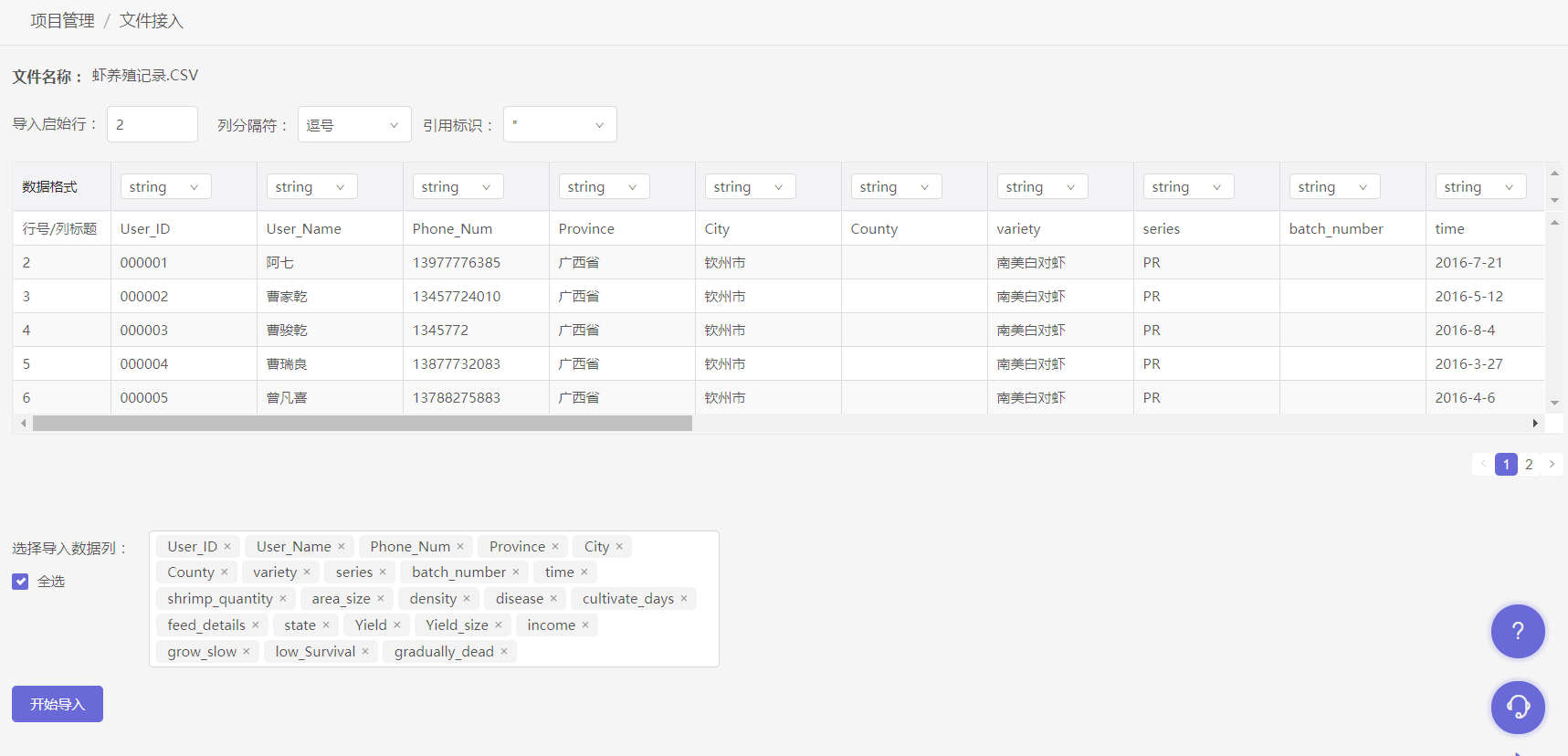
3.文件上传成功后可以进行预览,并进行一些导入设置:
- 1.导入启始行:由文件第几行开始导入。由于首行被强制判定为列标题,因此从第1行或第2行导入的结果是相同的;
- 2.分隔符号:选择文件所使用的分隔符号;
- 3.文本识别符号:选择文件所使用的文本识别符号,被符号标记的内容将被识别为文本而不是分隔符;
- 4.数据格式:根据实际数据需求,设置每一列的数据格式;若选择了错误的数据格式,例如字符串数据选择了int格式,会造成导入失败;
- 5.设置主时间字段:将某一列设置为时间维度列,即数据分析时的时间轴。此列的数据格式必须为date;
- 6.选择导入数据列:可自由选择将那些列进行导入,默认为全部导入。
日志导入
日志导入主要是用于快速采集/导入日志数据文件,通过简单的配置即可简单便捷实现日志数据的采集。用以做日志的查询和分析,同时也支持导入历史的日志数据,提供任意文件格式的支持。
创建项目
新建项目后,选择数据导入方式为日志接入,点击下一步即可进入日志接入的操作步骤。

日志接入操作流程
1.检验数据
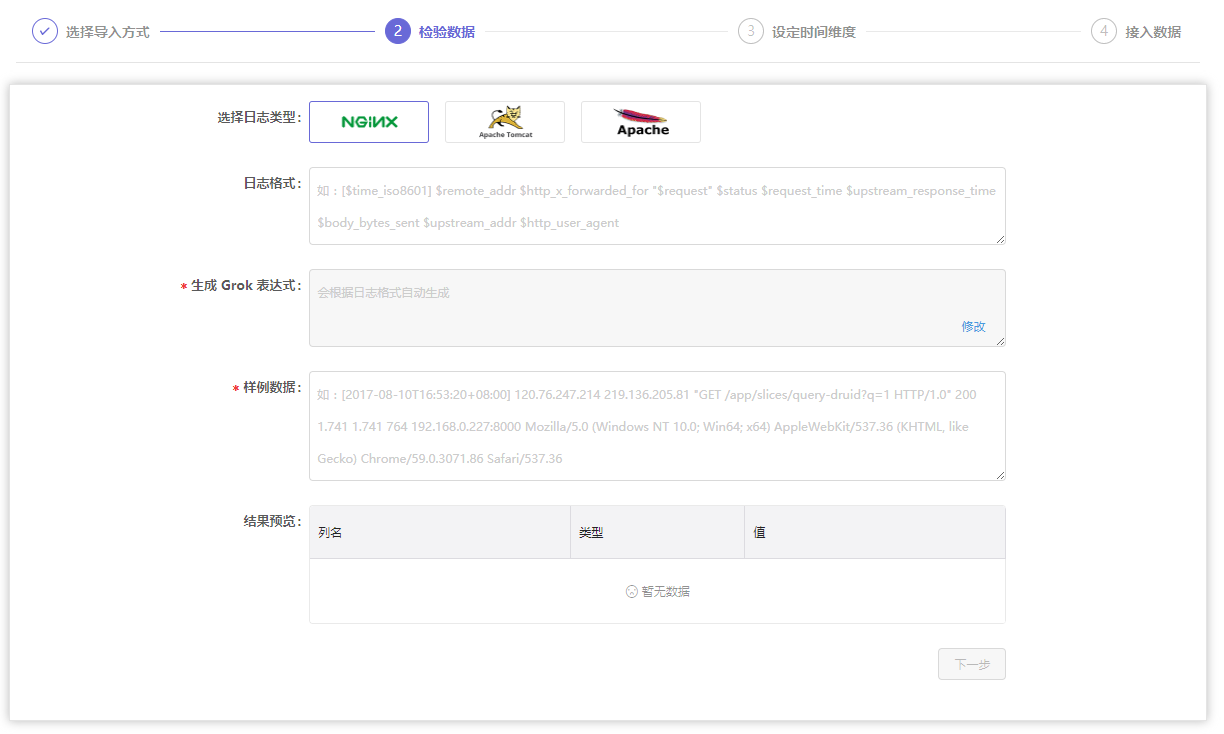
- 选择需要接入的日志数据类型:提供nginx、tomcat、apache 三种类型
- 日志格式:根据选择的日志类型进行数据格式的配置
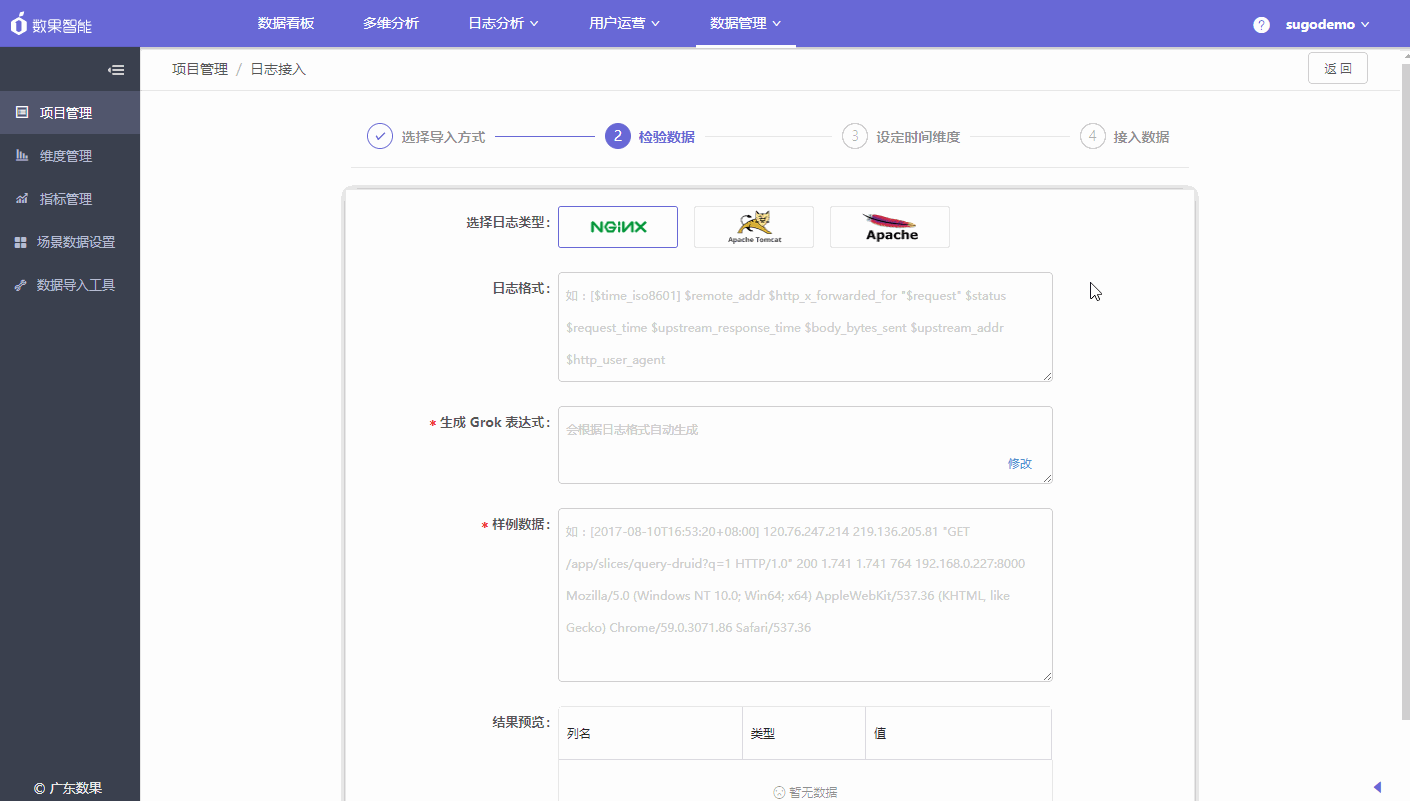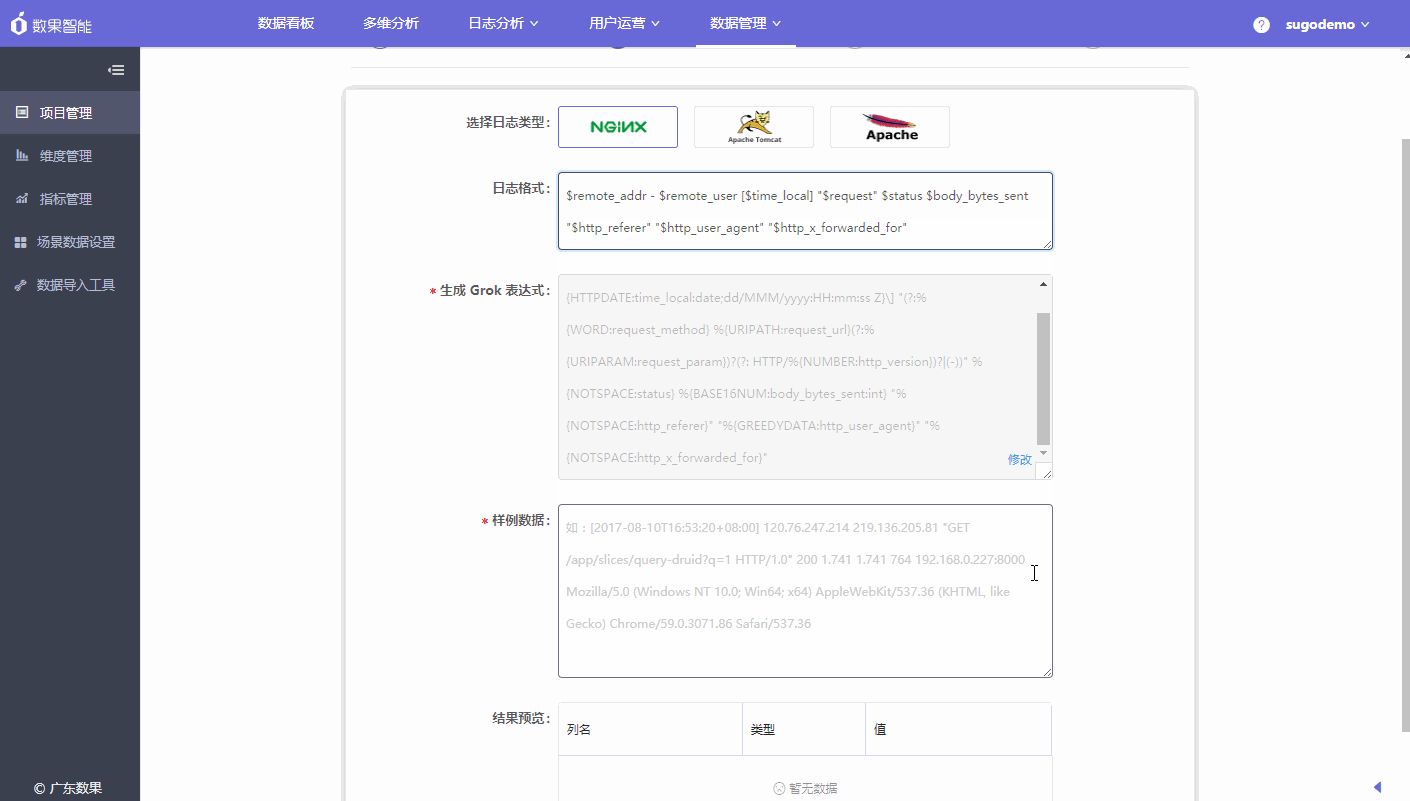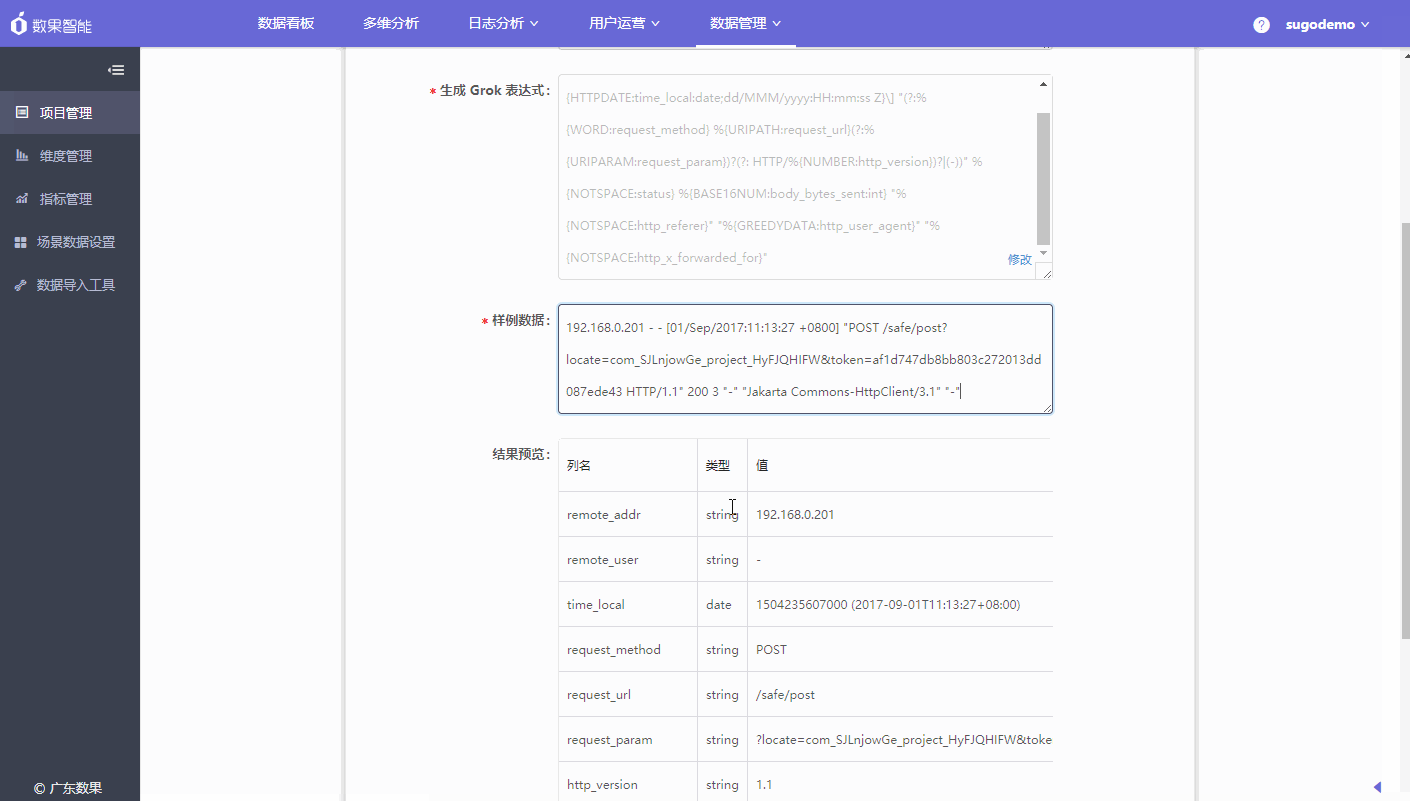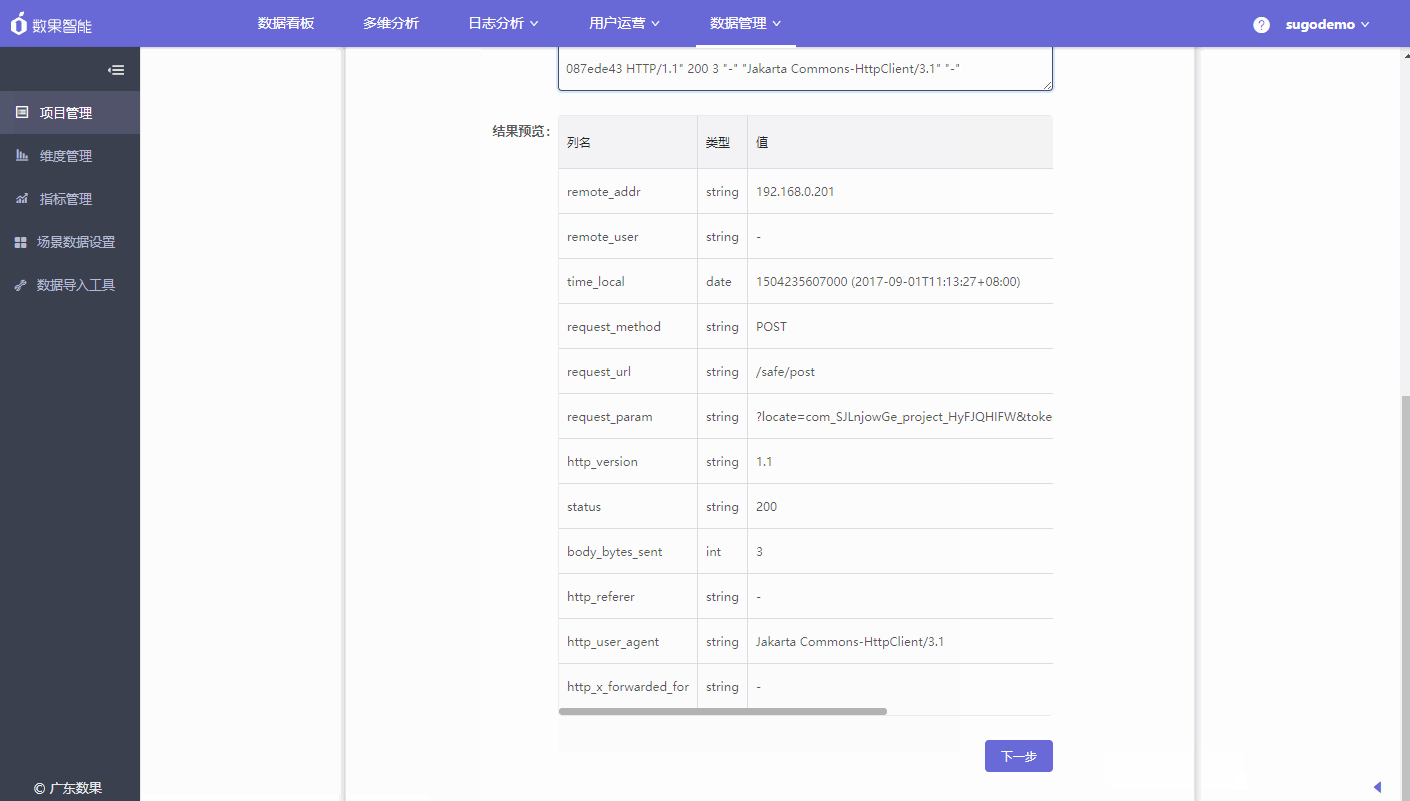
- 生成 Grok 表达式:填写日志格式后会自动生成,生成后可根据业务的情况点击进行修改。
- 样例数据:请输入您采集的服务器中其中的一条数据(截取格式对应的日志数据填入)
- 结果预览:若样例数据适配生成的Grok表达式,则自动生成结果预览。请核对字段与字段值是否匹配,如不匹配对日志格式或Grok表达式进行调整。
2.设定时间维度
- 选择时间列:时间维度是很重要的维度,请与Grok表达式中表示时间维度的维度名进行对应。默认会选择第一个时间类型的字段,可点击下拉修改;
- 预估每天数据量:对采集的服务器预估每天会采集的数据量。需要注意,填写该项能大大提高产品的使用性能。预估值将用于优化收集器的配置,越接近真实值,优化效果越好。

3.接入数据 日志数据的接入,数果提供两种方式接入:
- 方式一:下载Sugo-C 采集器
- 填写日志文件目录:被采集的日志所在的目录地址,请填写绝对地址。
- 填写日志文件名字:被采集的日志的文件名字,若为多个文件,可填写正则表达式来匹配。 服务端将按照基础配置中填写的信息进行配置并打包,点击下载按钮,下载Sugo-C日志采集器。
以下是下载采集器后的使用说明:
解压
下载后的文件以tar.gz为后缀,可使用通用的解压工具解压,或在命令行中,进入下载目录,使用如下命令进行解压:
tar -zxvf Sugo-C.tar.gz
使用
进入Sugo-C目录,使用bin目录下的脚本进行启动或停止采集器。
cd Sugo-C
启动:
bin/start.sh
停止:
bin/stop.sh
检测
在启动后,点击检测按钮测试采集器是否正常采集日志并上报。
自定义配置
conf目录内的collect.properties文件是采集器的配置文件,其配置参数如下:
参数说明
| 参数 | 默认值 | 说明 |
|---|---|---|
| file.reader.log.dir | 采集的日志所在目录 | |
| file.reader.log.regex | 采集的文件名正则表达式(单文件可直接填写文件名) | |
| file.reader.grok.patterns.path | ${user.dir}/conf/patterns | (可选)grok表达式配置文件路径 |
| file.reader.csv.dimPath | ${user.dir}/conf/dimension | csv维度配置文件,parser.class为io.sugo.collect.parser.CSVParser时生效 |
| file.reader.csv.separator | ,(逗号) | csv文件分隔符,空格分隔可填space, parser.class为io.sugo.collect.parser.CSVParser时生效 |
| file.reader.log.type | separate | 日志文件类型,日志若是以分离形式生成,则为separate,若是以单一文件不断增加内容的形式,则为only |
| file.reader.batch.size | 数据分批发送,此配置为每个批次的大小 | |
| file.reader.scan.timerange | 目录过期时间,采集程序不采集超过此时间的目录,单位(minutes) | |
| file.reader.scan.interval | 目录扫描时间,单位(ms) | |
| file.reader.threadpool.size | reader线程池大小,一个线程负责一个采集子目录 | |
| file.reader.host | InetAddress.getLocalHost().getHostAddress() | 采集日志所在机器的IP地址 |
| file.reader.grok.expr | grok 表达式 | |
| kafka.bootstrap.servers | 以部署Kafka的地址,格式为host:port,多个请以,分割 |
|
| writer.kafka.topic | Kafka的topic名称 | |
| writer.class | writer类名,数据写入到kafka使用io.sugo.collect.writer.kafka.KafkaWriter,发送到gateway使用io.sugo.collect.writer.gateway.GatewayWriter |
|
| writer.gateway.api | 发送到网关的接口 | |
| parser.class | parser类名,CSV文件使用 io.sugo.collect.parser.CSVParser,nginx日志建议使用io.sugo.collect.parser.GrokParser |
|
| reader.class | reader类名,暂时只有io.sugo.collect.reader.file.DefaultFileReader |
采集器的状态检测可能需要1分钟至10分钟不等,根据采集的数据量决定,数据量越大需要消耗的时间越长。 当检测成功后,即可开始日志分析。
- 方式二:上传文件
- 支持上传任意格式的文本文件
- 文件大小不超过 100M
采集日志数据需要注意的是:若数据为两个小时前的则视为历史数据,不会马上落地,所以无法马上从日志分析查询得到,您可以用过暂停项目触发历史数据的落地。
子项目
以某个项目数据为基础,通过设置筛选条件,将符合条件的数据划归一个新的项目。新的项目即为原项目的子项目。 子项目主要用于实现对数据的分权管理,将项目内的指定数据对指定人员开放。
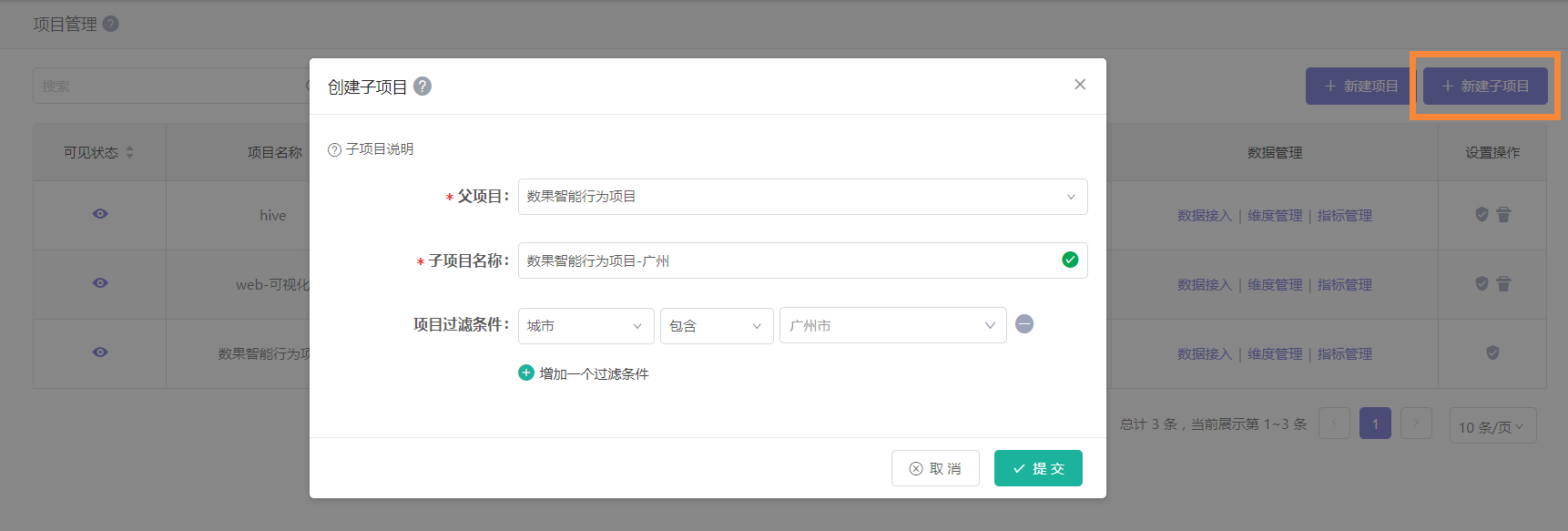
上图展示了一个子项目创建的例子: 我们希望广州分部的人员只能看到项目数据中关于广州市的部分。于是我们用城市作为过滤条件,将广州市的数据过滤出来,创建了一个名为“数果智能行为项目-广州”的子项目。
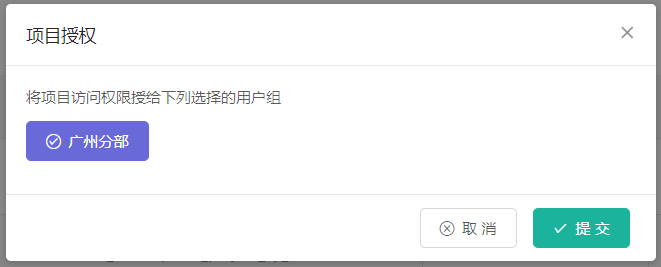
然后我们可以将新创建的子项目授权给指定的用户组。
用户库
用户库是存放项目登录用户信息的主要载体,如果没有设置,那么就算调用了登录接口,用户的登录信息也不会上报。所以我们需要先为每个项目设定好一个用户库,数果提供两种创建方式,选择哪个方式取决于您对网站/应用的用户分析实际情况。
方式一:创建新的用户库。那么该项目使用是一个全新的用户信息库,不受其他项目的用户信息影响。
假设有一个用户在项目1中第一次登录,那么会记录该用户在项目1的首次登录时间;若该用户在项目2中第一次登录,那么也会记录该用户在项目2的首次登录时间。
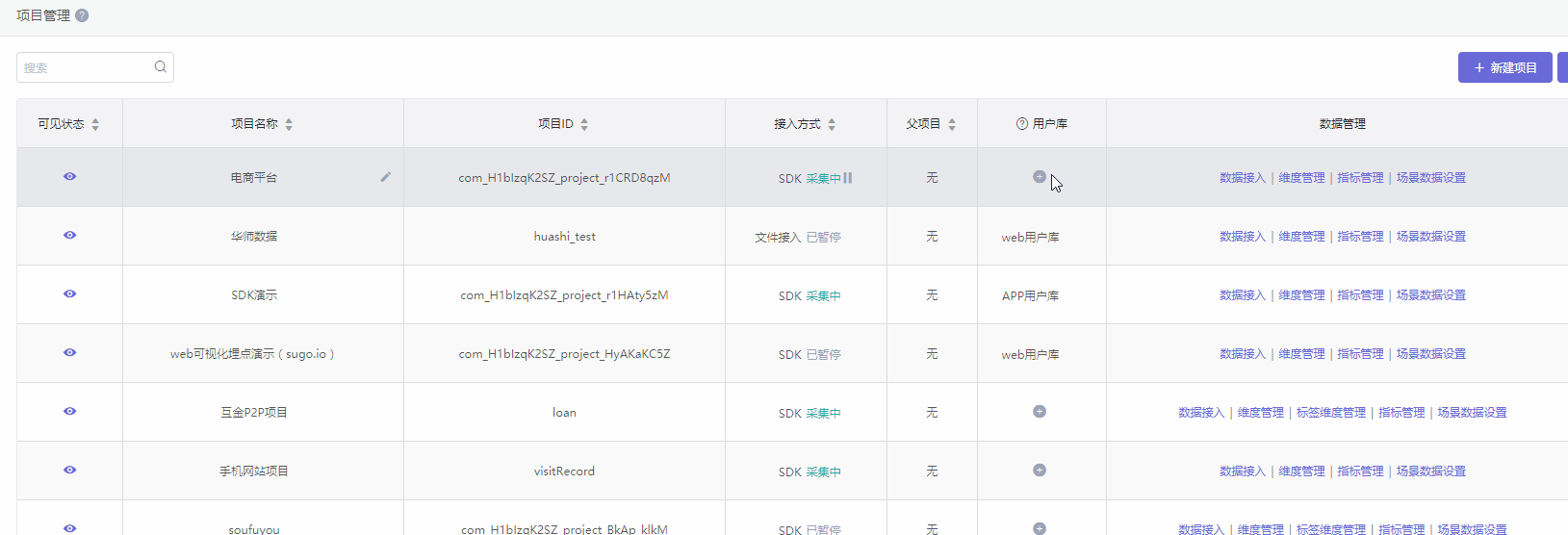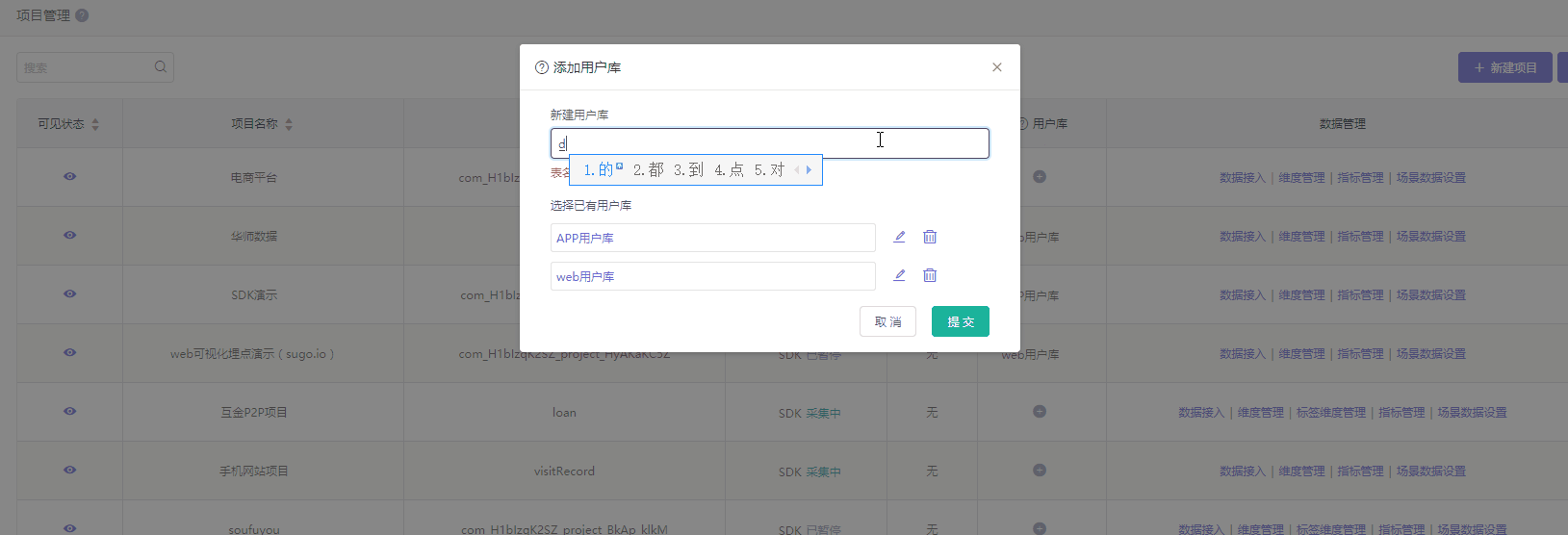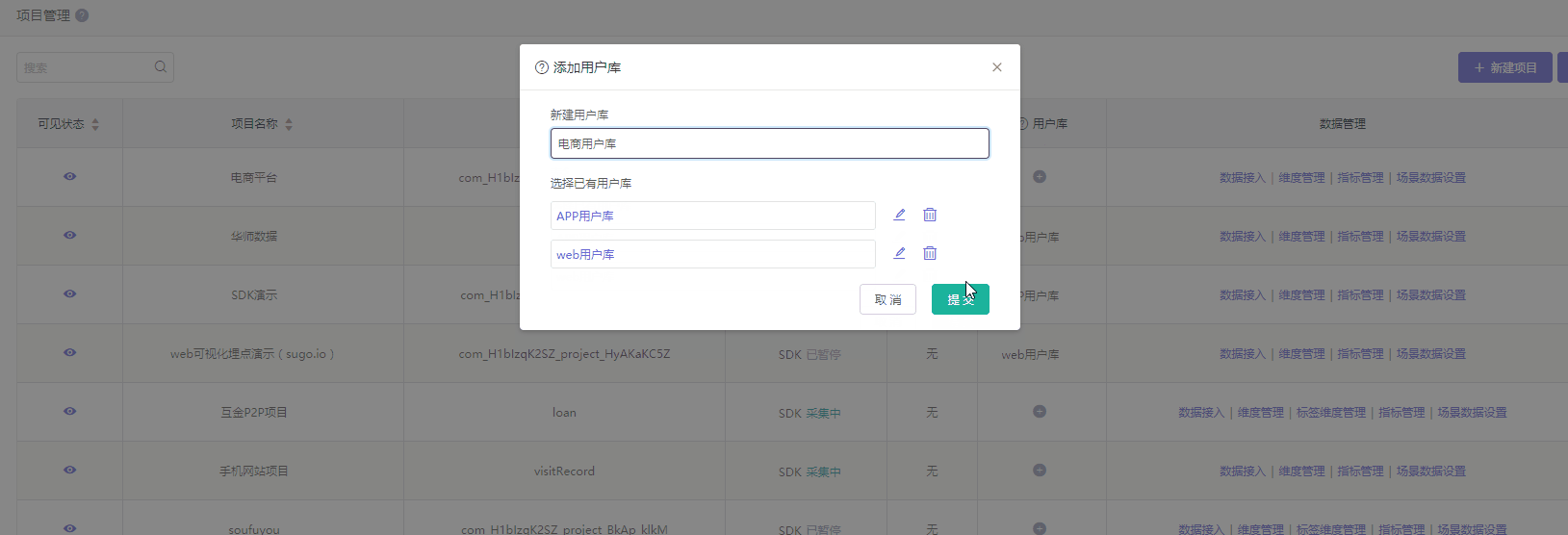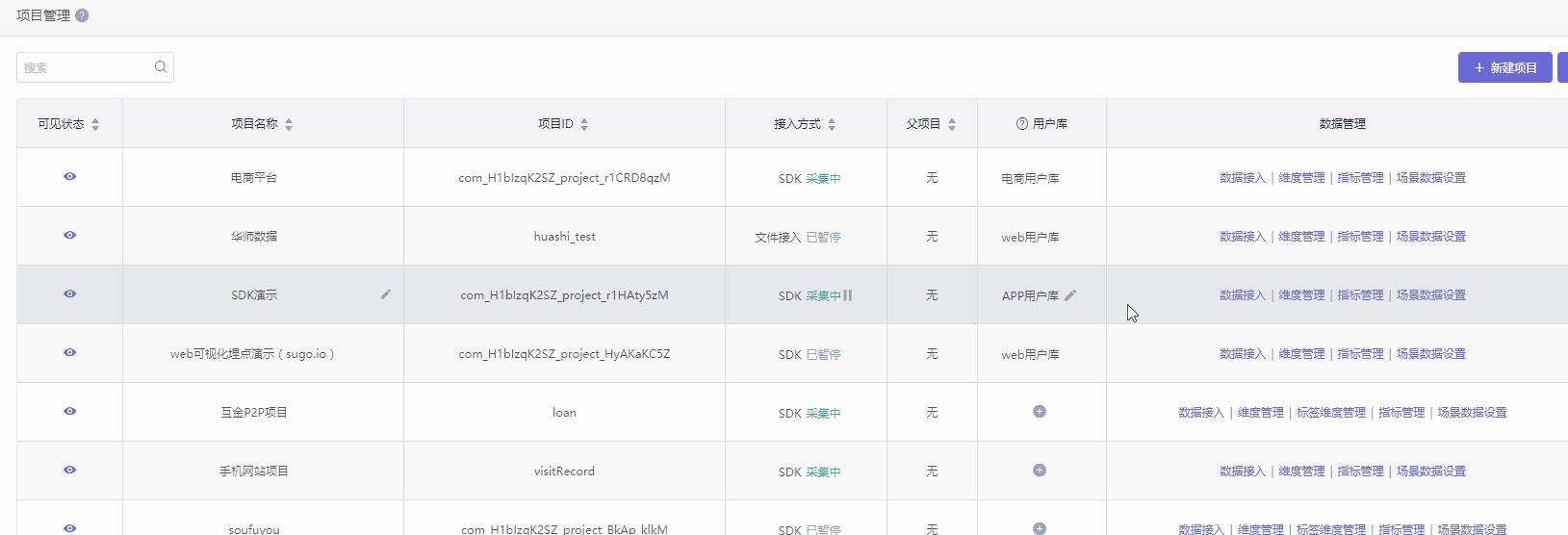
方式二:关联已有的用户库。那么用户库相同的项目则共用一个用户信息库。
假设一个用户在项目1中第一次登录,会记录该用户在项目1的首次登录时间;若该用户在项目2中也是第一次登录的,但该用户的首次登录时间依旧是在项目1中首次登录的时间。
