kafka接入
概要
本流程主要演示把
kafka的数据导入到Druid。前提:
- 部署好druid平台环境
- kafka集群已经部署好,数据已经正常写入特定的topic
- druid集群服务所在网络与kafka集群所在网络是相通的
1. kafka数据接入
本节主要说明如何使用非动态维的方式接入kafka中的json数据
第一步:编辑supervisor的json文件
从 kafka 接入数据到 druid 平台,需要通过发送一个 http post 请求到 druid 接入接口启动一个supervisor。
该 post 请求中包含 json 格式的请求数据信息。为了方便修改,建议先编辑一个 json 文件。
第二步:建立Supervisor
使用 curl 命令发送 post 请求。假设 json 文件名为 kafka.json,curl 命令如下:
curl -X POST -H 'Content-Type: application/json' -d @/tmp/json/kafka.json http://overlord_ip:8090/druid/indexer/v1/supervisor
/tmp/json/kafka.json: 详见
kafka.json
overlord_ip: druid的overlord节点ip地址,如果有多个overlord,必须指定leader的ip.
也可以通过网页来操作:
- 登录 overlord_ip:8090/supervisor.html
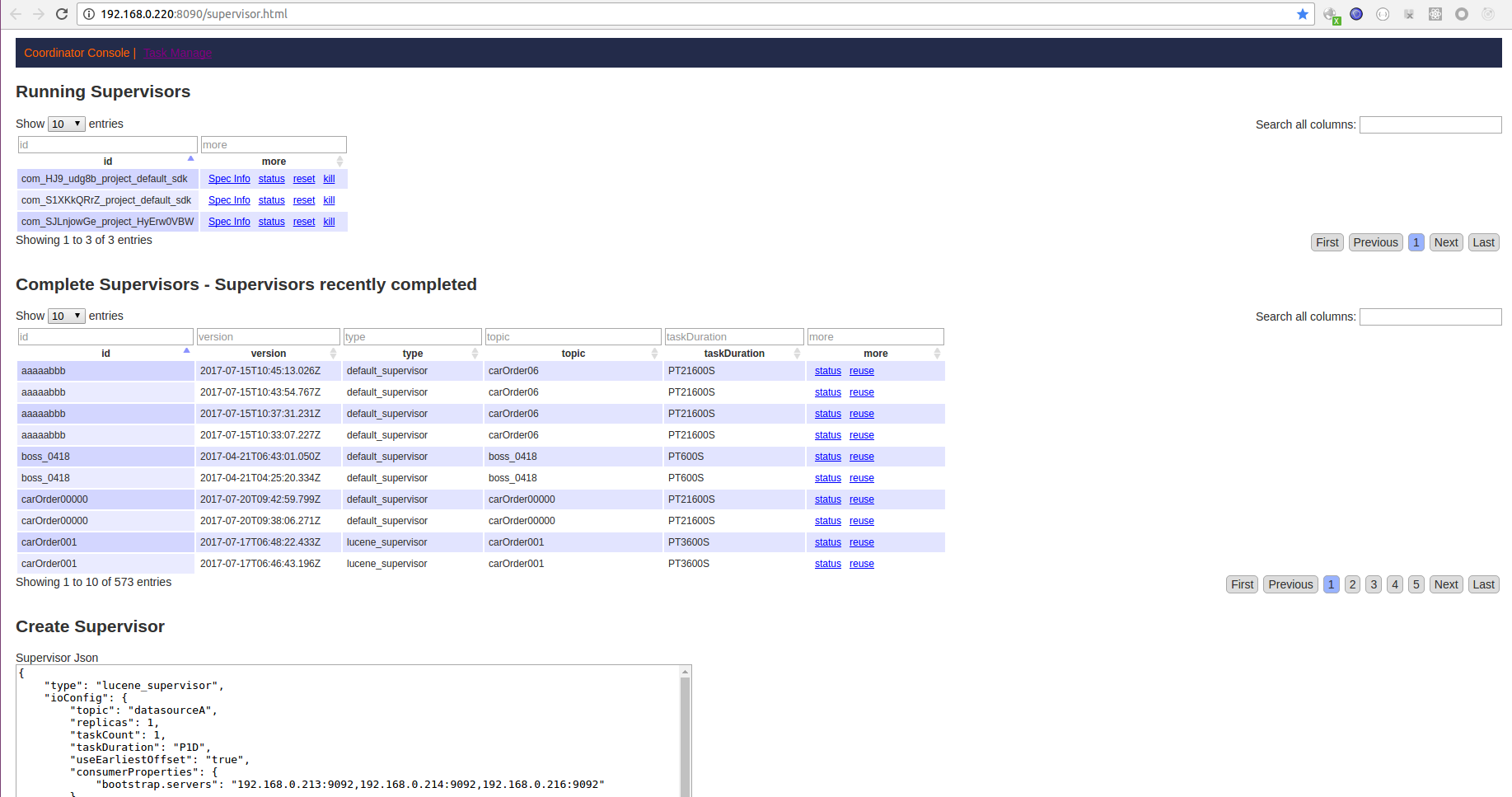
- 删除页面上原来文本框里的内容,将
kafka.json的内容复制,粘贴到文本框中,点击下面的Create Supervisor,即可创建Supervisor。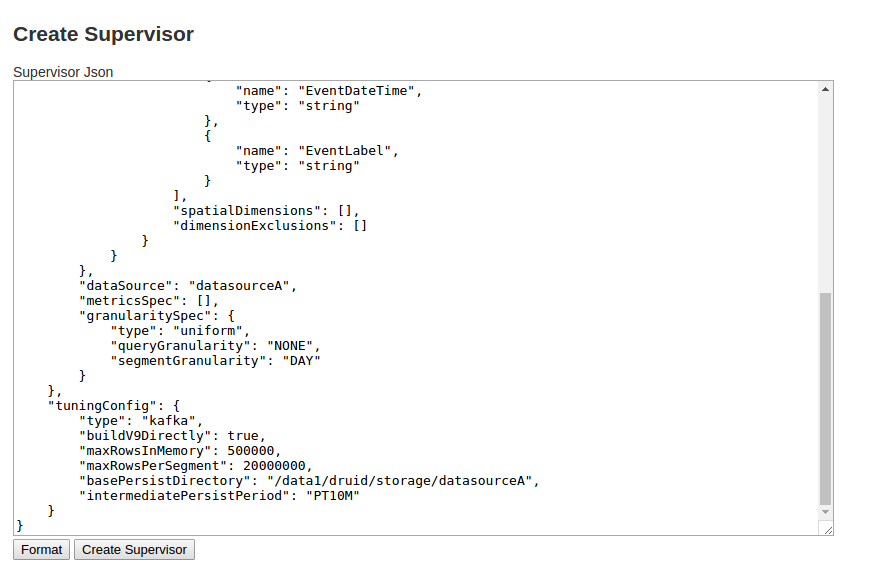
第三步:查看Task执行情况
- 查看日志
访问:
http://{OverlordIP}:8090/console.html,点击Task的日志,查看Task的执行情况OverlordIP: druid的overlord节点ip地址,如果有多个overlord,必须指定leader的ip.

查看执行结果
使用
sugo-plyql查询Task的执行结果,具体的命令格式为:./plyql -h {OverlordIP} -q 'select count(*) from {datasource}'OverlordIP: druid的overlord节点ip地址
datasource:json配置文件中定义的datasource名称如果查询的结果是"No Such Datasorce",则说明数据接入没有成功。
如果数据接入成功,那么查询到的结果如下:
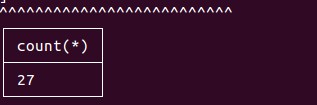
该数字为数据条数。关于
sugo-plyql的安装和使用,详见 sugo-plyql 使用文档
kafka.json的配置内容:
{
"type": "lucene_supervisor",
"dataSchema":{
"dataSource":"wiki",
"parser":{
"type":"string",
"parseSpec":{
"format":"json",
"dimensionsSpec":{
"dynamicDimension":false,
"dimensions":[
{"name": "id","type": "long"},
{"name": "age","type": "int"},
{"name": "province","type": "string"},
{"name": "birthday","type": "date","format":"millis"},
{"name": "salary","type": "long"},
{"name": "height","type": "double"},
{"name": "average","type": "float"},
{"name": "dimension1","type": "int"},
{"name": "dimension2","type": "int"},
{"name": "phone","type": "string"},
{"name": "car","type": "string"}
]
},
"timestampSpec": {"column": "dt","format": "millis"}
}
},
"metricsSpec":[],
"granularitySpec":{
"type": "uniform",
"segmentGranularity": "DAY",
"queryGranularity": "NONE"
}
},
"tuningConfig": {
"type": "kafka",
"maxRowsInMemory": 500000,
"maxRowsPerSegment": 20000000,
"reportParseExceptions":true
},
"ioConfig": {
"topic": "druid_test",
"consumerProperties": {
"bootstrap.servers": "192.168.0.223:9092,192.168.0.224:9092,192.168.0.225:9092"
},
"taskCount": 2,
"replicas": 1,
"taskDuration": "PT300S",
"useEarliestOffset": "true"
},
"writerConfig" : {
"type" : "lucene",
"maxBufferedDocs" : -1,
"ramBufferSizeMB" : 16.0,
"indexRefreshIntervalSeconds" : 6
}
}
参数说明:
| 属性名 | 值 | 类型 | 是否必需 | 默认值 | 说明 |
|---|---|---|---|---|---|
| type | lucene_supervisor | string | 是 | - | 指定接入类型,固定 |
| dataSchema | 参见DataSchema | json | 是 | - | 定义表结构和数据粒度 |
| ioConfig | 参见kafkaSupervisorIOConfig | json | 是 | - | 定义数据来源 |
| tuningConfig | 参见kafkaSupervisorTuningConfig | json | 是 | - | 配置Task的优化参数 |
| writerConfig | 参见WriterConfig | json | 是 | - | 配置数据段的写入参数 |
2. kafka动态维接入
本节主要说明如何使用动态维的方式接入kafka中的json数据, 常应用于接入kafka埋点数据
json数据样式:{"s|str":"dlo6ic","d|dt":1500714407574,"i|index":169}(d|dt的类型为date,格式为millis)- 使用动态维的规则 : key的信息包括两部分内容,字段类型+字段名称,字段类型与字段名称以|分割,多个组合以,分割。
- 字段类型映射:
i代表 int;s代表 string;l代表 long;d代表 date;f代表 float;p代表 double;t代表 text;I代表多值 int;S代表多值 string;L代表多值 long;D代表多值 date;F代表多值 float;P代表多值 double;
其它接入步骤与大体与kafka数据接入一样,此处不做赘述。仅提供接入的json样例
kafka动态维接入的 json配置内容:
{
"type": "lucene_supervisor",
"dataSchema":{
"dataSource":"wiki",
"parser":{
"parseSpec":{
"format":"json",
"dimensionsSpec":{
"dynamicDimension":true,
"dimensions":[]
},
"timestampSpec":{
"column":"d|dt",
"format":"millis"
}
},
"type":"standard"
},
"metricsSpec":[],
"granularitySpec":{
"type": "uniform",
"segmentGranularity": "DAY",
"queryGranularity": "NONE"
}
},
"tuningConfig": {
"type": "kafka",
"maxRowsInMemory": 500000,
"maxRowsPerSegment": 20000000,
"reportParseExceptions":true
},
"ioConfig": {
"topic": "druid_test_json",
"consumerProperties": {
"bootstrap.servers": "192.168.0.223:9092,192.168.0.224:9092,192.168.0.225:9092"
},
"taskCount": 2,
"replicas": 1,
"taskDuration": "PT300S",
"useEarliestOffset": "true"
},
"writerConfig" : {
"type" : "lucene",
"maxBufferedDocs" : -1,
"ramBufferSizeMB" : 16.0,
"indexRefreshIntervalSeconds" : 6
}
}
参数说明:
| 属性名 | 值 | 类型 | 是否必需 | 默认值 | 说明 |
|---|---|---|---|---|---|
| type | lucene_supervisor | string | 是 | - | 指定接入类型,固定 |
| dataSchema | 参见DataSchema | json | 是 | - | 定义表结构和数据粒度 |
| ioConfig | 参见kafkaSupervisorIOConfig | json | 是 | - | 定义数据来源 |
| tuningConfig | 参见kafkaSupervisorTuningConfig | json | 是 | - | 配置Task的优化参数 |
| writerConfig | 参见WriterConfig | json | 是 | - | 配置数据段的写入参数 |
3. kafka嵌套json接入
本节主要说明如何接入kafka中的嵌套json数据。
嵌套json格式数据如下
{
"fromhost-ip":"192.168.0.1",
"hostname":"test1.sugo.io",
"msg":{
"EventTime":"2019-01-01 12:30:00",
"Hostname":"ubuntu"
}
}
kafka接入嵌套数据的 json配置内容:
{
"type": "lucene_supervisor",
"dataSchema": {
"dataSource": "nested4",
"parser": {
"type": "string",
"parseSpec": {
"format": "nested",
"decollator": ".",
"timestampSpec": {
"reNewTime": "true"
},
"dimensionsSpec": {
"dimensions": [
{
"name": "fromhost-ip",
"type": "string"
},
{
"name": "hostname",
"type": "string"
},
{
"name": "EventTime",
"type": "string"
},
{
"name": "Hostname1",
"type": "string"
}
]
},
"parseSpec": {
"format": "json",
"flattenSpec": {
"useFieldDiscovery": false,
"fields": [{
"type": "ROOT",
"name": "fromhost-ip"
},{
"type": "PATH",
"name": "hostname",
"expr": "$.hostname"
},{
"type": "PATH",
"name": "EventTime",
"expr": "$.msg.EventTime"
},{
"type": "PATH",
"name": "Hostname1",
"expr": "$.msg.Hostname"
}
]
}
}
}
},
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "DAY"
}
},
"tuningConfig": {
"type": "kafka",
"maxRowsInMemory": 500000,
"maxRowsPerSegment": 20000000,
"taskDealRowCount": 100000000,
"consumerThreadCount": 1
},
"ioConfig": {
"topic": "winsys_log_nest_json",
"replicas": 1,
"taskCount": 1,
"taskDuration": "PT86400S",
"consumerProperties": {
"bootstrap.servers": "192.168.0.223:9092,192.168.0.224:9092,192.168.0.225:9092"
},
"useEarliestOffset": true
},
"writerConfig" : {
"type" : "lucene",
"maxBufferedDocs" : -1,
"ramBufferSizeMB" : 16.0,
"indexRefreshIntervalSeconds" : 6
}
}
| 属性名 | 值 | 类型 | 是否必需 | 默认值 | 说明 |
|---|---|---|---|---|---|
| type | lucene_supervisor | string | 是 | - | 指定接入类型,注意:lucene_index也支持嵌套数据接入 |
| dataSchema | 参见DataSchema | json | 是 | - | 定义表结构和数据粒度 |
| ioConfig | 参见kafkaSupervisorIOConfig | json | 是 | - | 定义数据来源 |
| tuningConfig | 参见kafkaSupervisorTuningConfig | json | 是 | - | 配置Task的优化参数 |
| writerConfig | 参见WriterConfig | json | 是 | - | 配置数据段的写入参数 |
特殊参数说明:
dataSchema.parser.parseSpec.formatparse类型配置为嵌套的"nested".dataSchema.parser.parseSpec.decollator分割符默认为".",在本文档是将嵌套的json打平,所以此配置无效.如果想将嵌套的json解析后,保留原来的嵌套格式,比如解析以上json后显示的字段包含"msg.EventTime",则需要此配置.dataSchema.parser.parseSpec.timestampSpec配置时间戳列,如果数据中没有时间列,可使用当前时间作为时间列,详见timestampSpec.dataSchema.parser.parseSpec.dimensionsSpec配置解析后的维度信息.dataSchema.parser.parseSpec.dimensionsSpec.dimensions此处需要定义所有的维度信息,没在此处定义的维度数据将会被丢弃.注意不能存在相同名称的维度,即使是大小写的区别也不可以.dataSchema.parser.parseSpec.parseSpec配置解析嵌套json的解析器.dataSchema.parser.parseSpec.parseSpec.format此处配置为json.dataSchema.parser.parseSpec.parseSpec.flattenSpec配置json解析信息.dataSchema.parser.parseSpec.parseSpec.flattenSpec.useFieldDiscovery使用自动发现json根节点下的信息,如果配置为true,将自动解析到上述json中的fromhost-ip和hostname.而不需要在fields中配置.dataSchema.parser.parseSpec.parseSpec.flattenSpec.fields提取嵌套json中的信息.dataSchema.parser.parseSpec.parseSpec.flattenSpec.fields.type提取的方式,可选PATH或ROOT.PATH以jsonpath方式提取信息.ROOT从根节点提取信息,比如fromhost-ip.
dataSchema.parser.parseSpec.parseSpec.flattenSpec.fields.namejson中的key,比如hostname.dataSchema.parser.parseSpec.parseSpec.flattenSpec.fields.expr当type为PATH时有效,具体格式可参考jsonpath,比如$.msg.EventTime.