数据段合并
概要:
本例子主要用于对特定粒度
interval下的分段segment进行合并,比如在粒度为DAY的datasource下某一天的记录有两个segment,在这种情形下可以按照本流程对其进行合并,可以起到减少冗余空间、加快查询的等优化效果。前提:
- Druid中已存在相应的datasource
- datasource中的记录有大于等于2的分段碎片(shard)
以下以广东数果科技有限公司为例,展示合并datasource全过程操作指引:
第一步:查找在druid中的目标datasource
- 在
http://192.168.0.222:8081/#/datasources页面上查找要合并的 datasource。 例如要合并的datasource是test061901
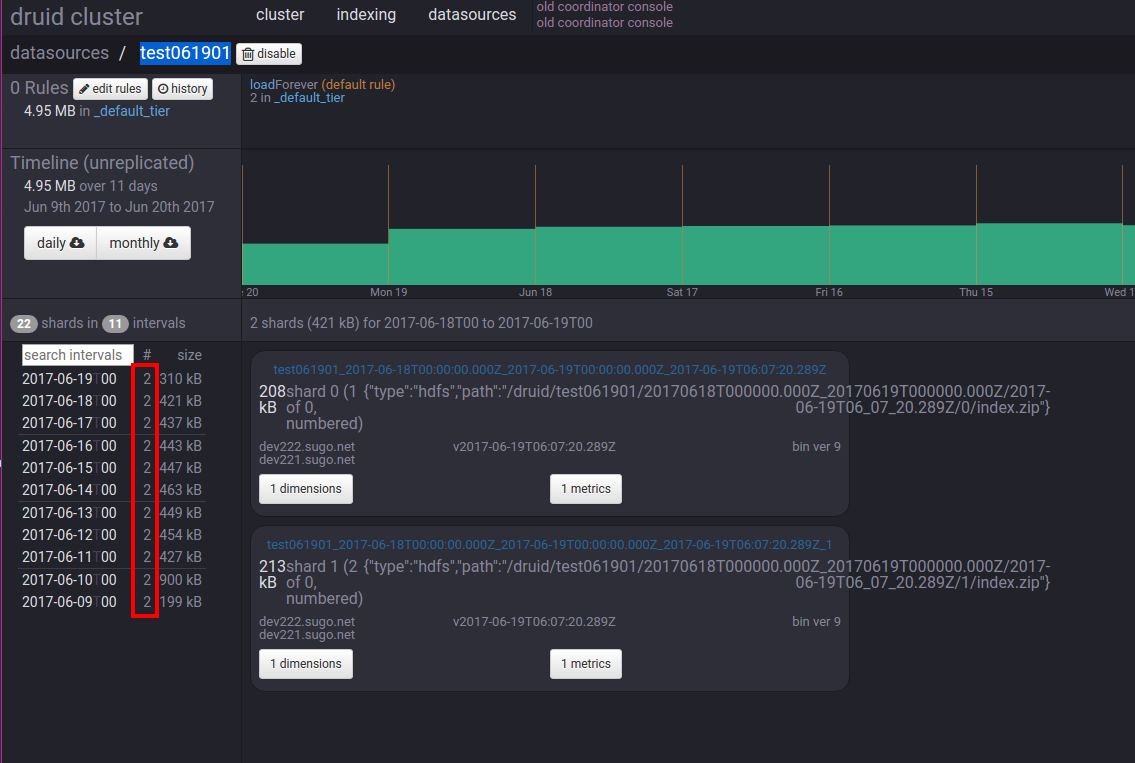
注意:上图红框内的数字”2“代表该条记录包含两个分段碎片。
第二步: 创建、编辑、保存LuceneMergeTask.json文件说明
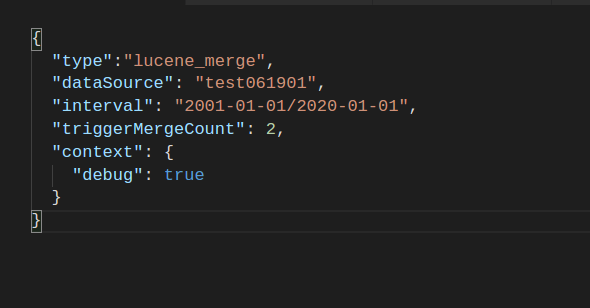
第三步:执行命令上传json文件,创建Task任务
- 在命令行中使用
cd命令进入第二步创建的json文件所在的目录 使用
curl命令上传json文件:curl -X 'POST' -H 'Content-Type:application/json' -d @LuceneMergeTask.json http://{overlordIP}:8090/druid/indexer/v1/taskoverlordIP: druid的overlord节点ip地址,如果有多个overlord,必须指定leader的ip.
LuceneMergeTask.json task配置文件,详见下文
第四步:进入overlord服务的Task列表页面,查看Task日志信息,观察Task合并情况。
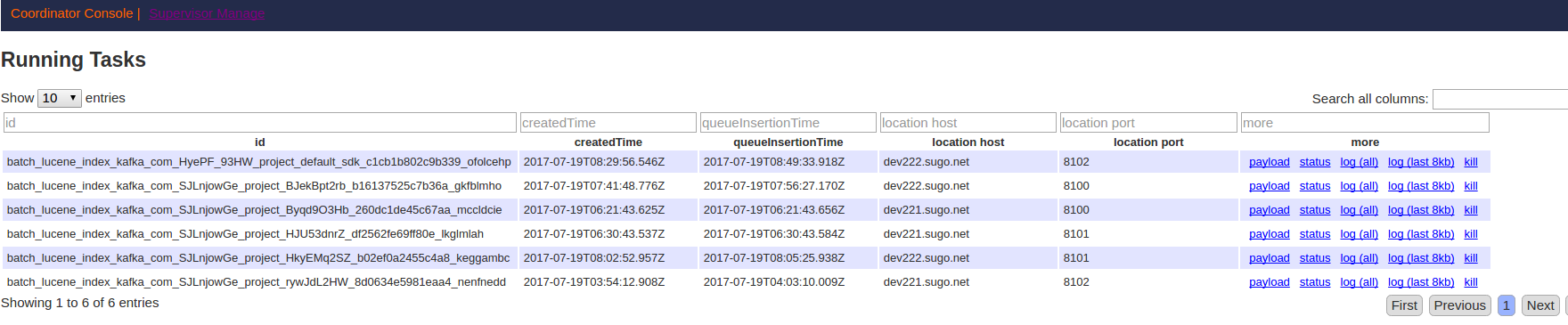
访问地址:
http://{overlordIP}:8090/console.htmloverlordIP: druid的overlord节点ip地址
第五步:在需要停止task时,可以发送如下http post请求停止task任务
curl -X 'POST' -H 'Content-Type:application/json' http://{overlordIP}:8090/druid/indexer/v1/task/{taskId}/shutdown
overlordIP: druid的overlord节点ip地址
taskId: 在
http://{overlordIP}:8090/console.htmltask详细页面对应 id 列的信息
第六步:查看合并结果
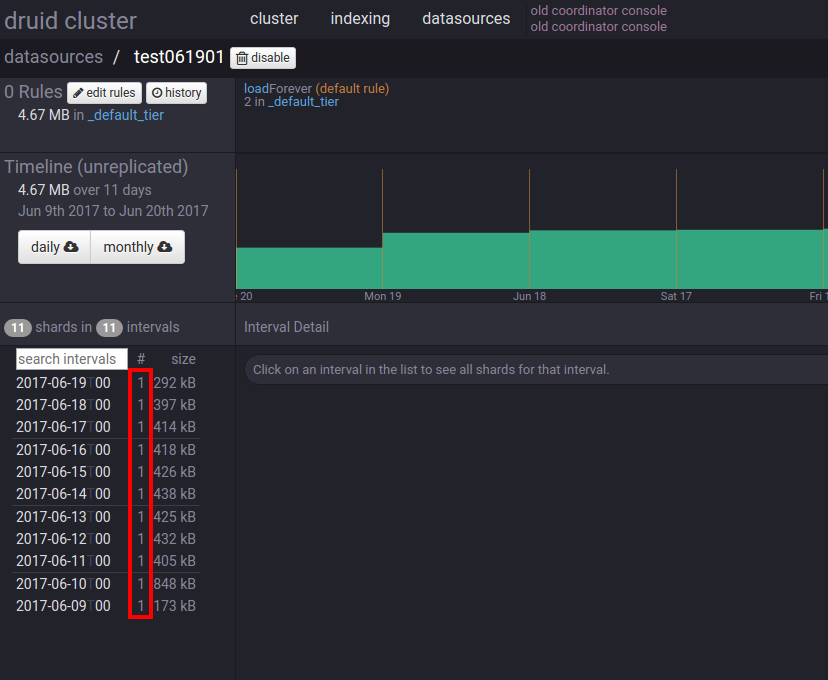
可以看到,目标datasource的每条记录都变成只有一个分段碎片了
LuceneMergeTask.json详细配置如下:
{
"type":"lucene_merge",
"dataSource": "test061901",
"interval": "2017-06-01/2017-06-30",
"triggerMergeCount": 2,
"mergeGranularity":"DAY",
"maxSizePerSegment":"800MB",
"context": {
"debug": true
}
}
| 字段 | 描述 |
|---|---|
| type | 指定任务类型 |
| dataSource | 要合并的datasource名称 |
| interval | 需要进行合并的时间间隔,在间隔范围外的不进行合并 |
| triggerMergeCount | 设定触发合并的段的数量,超过该值才触发合并,默认为2,一般不需要修改 |
| mergeGranularity | 指定合并的粒度,可选项有:SECOND、MINUTE、FIVE_MINUTE、TEN_MINUTE、FIFTEEN_MINUTE、HOUR、SIX_HOUR、DAY、WEEK、MONTH、YEAR |
| maxSizePerSegment | 指定合并后数据段的最大值 |
| context | 指定任务的其它环境参数 |